
「RAGはもう古い。1Mトークンのコンテキストに全部放り込めば済む」。最近、AI業界でそんな議論を目にする機会が増えてきました。主要な生成AIが次々と長文コンテキストに対応し、理論上は社内文書をまるごとプロンプトに載せて質問することが可能な時代に入っています。
では、RAG(検索拡張生成)はもう不要なのでしょうか。本記事では、この議論に真正面から向き合い、企業のナレッジベース用途では「用途によって使い分けるのが現時点の最適解」 という結論を、技術的な観点と具体的な数値で解説します。
この記事で分かること
- 長文コンテキスト革命と「RAG不要論」が登場した背景
- 「全部食わせれば済む」論が企業ナレッジベースで直面する5つの壁
- 長文コンテキストが本当に光る領域
- ハイブリッド型という現実解と、設計時の判断軸
長文コンテキスト革命 -- AIに"全部読ませる"が現実に
ここ1〜2年で、大規模言語モデル(LLM)のコンテキストウィンドウ(=1回のやり取りで扱える情報量)は劇的に拡大しました。
- 主要な生成AIが 100万(1M)〜200万(2M)トークン 級の長文コンテキストに対応
- 日本語テキストに換算すると、1Mトークンで原稿用紙約3,500枚、書籍10〜15冊分 に相当
- 画像や表、PDFもマルチモーダルで読み込めるモデルが増加
これは、ほんの数年前には想像もできなかった規模です。GPT-3時代(2020年)のコンテキストウィンドウが4,000トークン程度だったことを考えると、3桁近いスケールアップ が起きています。
この急速な進化を受けて、AIコミュニティでは自然にこんな声が上がり始めました。「そんなに長く読めるなら、社内文書を全部プロンプトに放り込めば、わざわざRAGで検索する必要はないのでは?」
RAGの仕組みや基本的な考え方は、RAGとは何かで詳しく解説しています。本記事ではその知識を前提に、「RAG不要論」の是非を検討していきます。
「全部食わせれば済む」論の実態 -- 理論と現実のギャップ
結論から言えば、個人利用や小規模な文書群であれば、長文コンテキストに全部放り込む運用は現実的 です。しかし、企業のナレッジベース用途に目を向けると、いくつもの壁に突き当たります。ここでは代表的な5つを見ていきます。
壁1: コスト -- 毎クエリ100MBを送り続けるのか
長文コンテキストの最大の難点はコストです。プロンプトに載せたトークンには、原則として毎回課金される からです。
仮に、社内文書を100MB(テキスト換算でおよそ50MB = 2,500万字)保有している企業を想定してみましょう。これはトークン換算で 約1,600万トークン 規模になります。現行の1Mコンテキストには収まりませんが、仮に今後2M、5Mと拡張されていったと仮定して計算します。
| シナリオ | 1クエリあたり入力トークン | 1クエリのコスト感 | 月間1万クエリの場合 |
|---|---|---|---|
| RAG(関連チャンクのみ) | 数千〜数万 | 数円未満 | 数万円 |
| 長文コンテキスト全投入 | 100万〜1,600万 | 数百〜数千円 | 数百万〜数千万円 |
プロンプトキャッシュ(同一プロンプトの再送を割り引く仕組み)を使えば、キャッシュヒット時の費用は 本来の1/10程度まで圧縮 できます。ただし、これでも1日数百万円規模のコストは簡単には消せません。キャッシュが効かないファースト呼び出しや、文書更新後の再キャッシュにはフルコストがかかる点も見逃せません。
「関連する数ページだけを送るRAG」と「毎回全部を送る長文コンテキスト」では、費用のオーダーが文字通り桁違い になります。
壁2: 容量 -- 1M〜2Mでも中堅企業の全文書は入らない
そもそも、長文コンテキストに全社の文書が収まるかという問題があります。
- 1Mトークン ≒ 書籍10〜15冊分
- 中堅企業1社の社内文書は、PDF1,000〜5,000件、数千万〜数億トークン規模 になることが一般的
- 議事録・Slackログ・顧客メールまで含めれば、さらに一桁増える
つまり、1M〜2Mでは「全部食わせる」に足りないのが現実です。長文コンテキストは確かに大きな進歩ですが、「企業ナレッジをまるごと保持するストレージ」としてはまだ小さいのです。
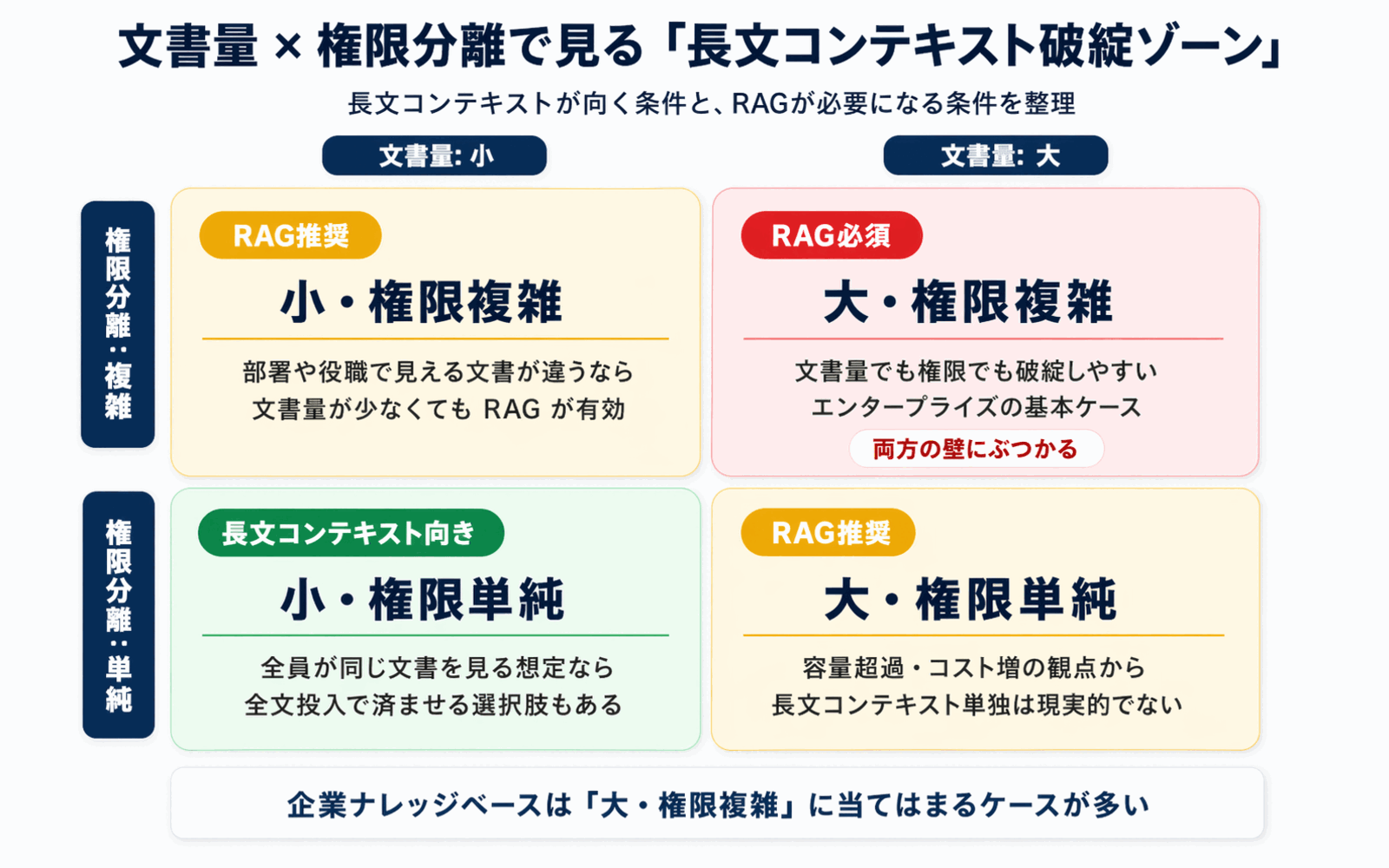
壁3: 権限分離 -- 誰もが同じ文書を見られるわけではない
企業ナレッジベースには、ユーザーや部署ごとにアクセス権が異なる という大前提があります。
- 人事部しか見られない給与・評価資料
- 特定プロジェクトの機密資料
- 役員・幹部限定の経営資料
長文コンテキスト型のアプローチでは、理論的には ユーザーごとに異なる文書セットをプロンプトに組み立てる 必要があります。しかしこれは、
- ユーザーごとにキャッシュが分かれてコスト効率が落ちる
- 権限チェックのロジックがプロンプト生成層に入り込み、設計が複雑化する
- 「この情報を載せていいか?」の判断ミスがそのまま情報漏洩につながる
といった課題を抱えます。権限とアクセス制御が前提の企業用途では、検索段階でフィルタできるRAG型のほうが素直 です。社内ナレッジをAIに聞けるものしりAIが採用しているフォルダ単位のアクセス制御についても、セキュリティポリシーで仕組みを公開しています。
壁4: Lost in the Middle -- 長ければ長いほど精度が下がる現象
「長文コンテキストに入れれば、ちゃんと読んでくれる」と思いたくなりますが、実際には LLMはプロンプトの先頭と末尾に強く注目し、中央部分の情報を取りこぼしやすい ことが、複数の研究で指摘されています。この現象は "Lost in the Middle" と呼ばれています。
- 特に ピンポイントに1事実を引く質問(「Xの申請締切は?」など)で劣化が顕著
- 文書数・文書長が増えるほど精度低下が加速する傾向
- モデルによっては1Mコンテキスト対応でも、実質的に高精度で扱えるのは数十万トークン程度という指摘もある
RAGは 関連度の高い数ページだけをプロンプトに載せる ため、Lost in the Middle の影響を受けにくい設計になっています。「大量の文書から特定の一文を引く」タスクでは、むしろRAGのほうが強いのです。
壁5: 更新 -- 文書を1件追加するたびに何をするか
企業ナレッジは毎日のように更新されます。規程改定、新製品リリース、議事録追加。文書を1件追加するたびに何が起きるかを比較してみましょう。
| アプローチ | 文書追加時の動き |
|---|---|
| RAG | 追加分だけをベクトル化してインデックスに登録 |
| 長文コンテキスト全投入 | プロンプト全体を作り直し、キャッシュも再構築 |
「差分だけを処理できるか」 は、運用コストに直結する重要な観点です。RAGは差分更新に強く、長文コンテキスト全投入は差分更新に弱い、という明確な性質の違いがあります。
長文コンテキストが本当に光る領域
ここまで長文コンテキストの課題を見てきましたが、これは「使い物にならない」という話ではありません。むしろ、RAGが苦手な領域で長文コンテキストは圧倒的な力を発揮します。
1. 小規模で完結するナレッジ
数件〜数十件のドキュメントで成り立つナレッジは、長文コンテキストに全部入れてしまうのが最速・最強です。たとえば 商品マニュアル1冊、契約書1通、議事録1本 を対象にした質問応答では、検索インデックスを作るよりプロンプトに貼り付けるほうが速く、精度も安定します。
2. 文書内の深い推論・横断分析
1つの長文の中で「A章とB章を突き合わせて矛盾を指摘してほしい」「全体を要約してほしい」のようなタスクは、文書全体を同時に見る必要がある ため、RAGのチャンク分割では不利になります。長文コンテキストの独擅場です。
3. 複数文書をまたいだ統合的な分析
関連する10〜30件程度の文書を横断して、「これらに共通するパターンを抽出してほしい」といった分析系タスクも、長文コンテキストが向いています。
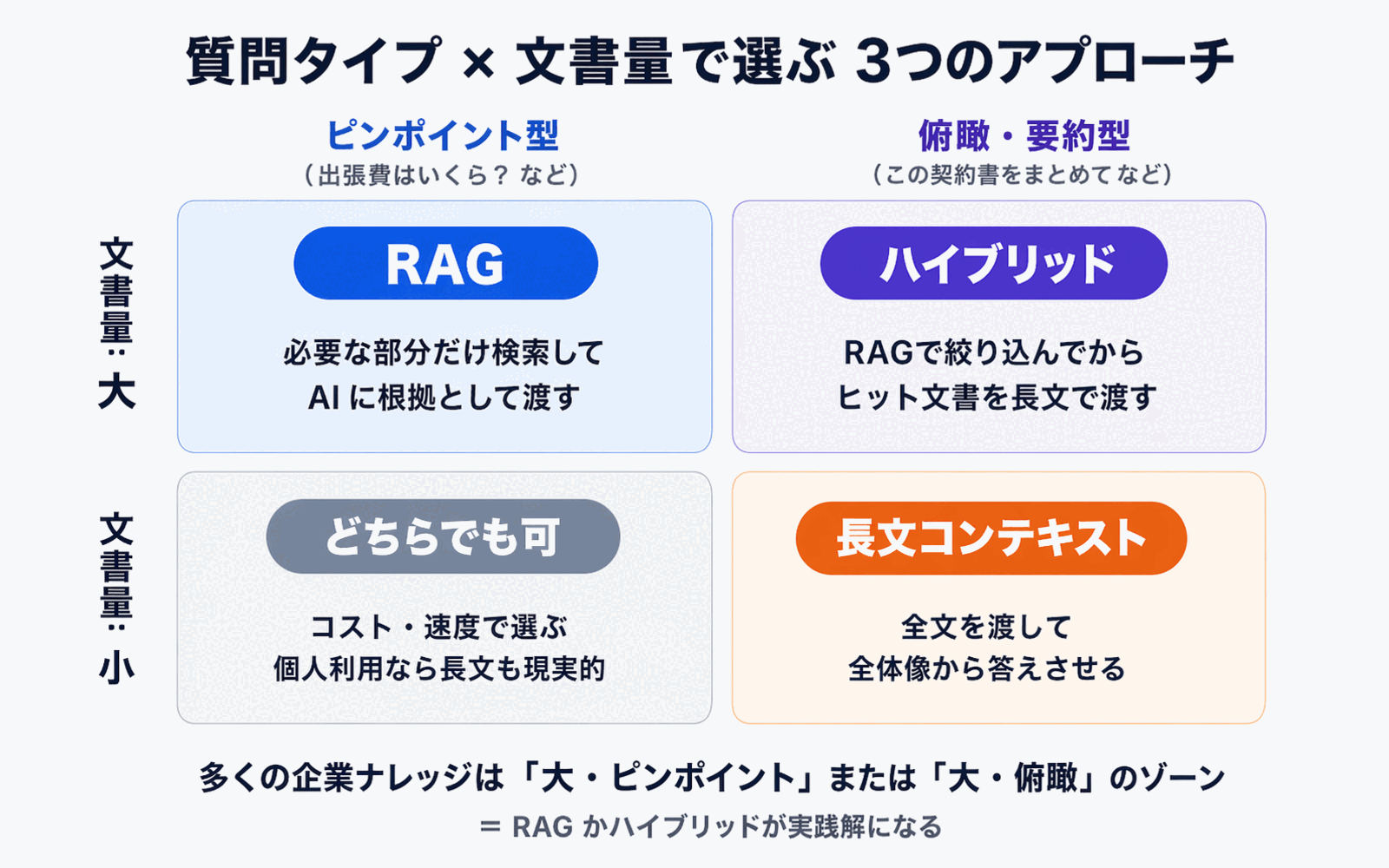
ピンポイント検索型タスクはRAG、全体俯瞰型タスクは長文コンテキスト -- こう整理すると、両者の棲み分けが見えてきます。
現実解はハイブリッド -- 3つのアプローチの使い分け
こうした特性を踏まえ、実務では次の3つのアプローチを組み合わせる設計が主流になりつつあります。
1. 古典的RAG -- 大規模ナレッジの検索応答の基盤
従来型のRAGは、「大量の文書から数ページだけを抜き出して答える」 というユースケースにおいて、今なお最も費用対効果の高い選択肢です。その心臓部にあたるセマンティック検索(意味検索)とは何か、社内文書をAIで探す仕組みは、図解付きの別記事で詳しく解説しています。
2. 長文コンテキスト活用 -- 小規模・深掘り用途
対象ドキュメントが絞り込めていて、文書内の深い推論が必要な場面では、長文コンテキストをそのまま使うのが最短ルートです。
3. ハイブリッド型(Agentic RAG / RAG + Long Context / CAG)
最近特に注目されているのがハイブリッド型です。代表的な発展形として、
- Agentic RAG: AIエージェントが「まず検索 → 足りなければ追加検索 → 必要なら全文を読みに行く」と自律的に判断するパターン
- RAG + Long Context: RAGで関連文書群を絞り込み、その中身は長文コンテキストで丸ごと読ませるパターン(チャンク分割の弊害を抑えられる)
- Cache-Augmented Generation(CAG): 頻出する文書群をあらかじめプロンプトキャッシュに載せ、検索ステップを省略しつつコストを抑えるパターン
があります。これらは 「RAGか長文コンテキストか」ではなく、両者を統合した設計 と捉えるのが正確です。
4. Corpus2Skill -- ドキュメント構造そのものをナビゲーションに使う
近年もう一つ注目されているのが、ドキュメントの章・節・項といった元から備わった階層構造を、LLMが tool として navigate するアプローチ です。代表例として、ものしりAIが採用している Corpus2Skill(skillモード)があります。
これはRAG・長文コンテキスト・ハイブリッドのいずれとも異なる第四の方向性です。ベクトル空間に押し込む代わりに、もともと人間向けに整理されているドキュメント構造をそのまま意味的な目次として使う ため、出典明示が常に階層的に行え、再ベクトル化の運用負荷もありません。中規模・構造化された社内文書群(規程・マニュアル・FAQ)に強く、prompt cachingとの相性も良好です。
ものしりAI自身、RAG・長文コンテキスト・ハイブリッドのすべてを検証した結果としてこの設計に至っています。詳しい技術判断と移行の経緯はRAGをやめました -- ものしりAIがCorpus2Skill(skillモード)に全面移行した理由で公開しています。
企業ナレッジベースを設計するときの5つの判断軸
では、自社のナレッジベースを設計するときに何を基準に選べばよいか。次の5つの軸で整理することをおすすめします。
1. 文書量
| 規模 | 推奨アプローチ |
|---|---|
| 数件〜数十件 | 長文コンテキスト中心 |
| 数百件〜数千件 | RAG中心、必要に応じハイブリッド |
| 数万件以上 | RAG必須 |
2. 権限分離の要否
部署別・役職別にアクセス権を分ける必要がある場合は、検索段階でフィルタできるRAG型がほぼ必須 になります。
3. 更新頻度
日次・時間次で文書が追加・更新される環境では、差分更新に強いRAGが運用しやすくなります。
4. コスト許容度
問い合わせ件数が多い(例: 全社員が毎日使う)場合、毎クエリで大量トークンを送る長文コンテキスト運用は 予算を圧迫しやすい ため慎重な見積もりが必要です。
5. 質問タイプ
- 「特定の一事実を引く」質問が中心 → RAGが有利
- 「文書全体を俯瞰する」質問が中心 → 長文コンテキストが有利
- 両方混在 → ハイブリッド型
ものしりAI自身も同じ問いに直面し、RAG・長文コンテキスト・ハイブリッドのすべてを検証した結果、社内ドキュメント特有の構造を活かす Corpus2Skill(skillツリー)という第四の選択肢にたどり着きました。詳しい技術判断はこちら。料金体系については料金プラン、主要機能は機能一覧をご覧ください。
まとめ
本記事では、長文コンテキスト時代における「RAG不要論」の是非と、企業ナレッジベースの設計方針についてお伝えしました。ポイントを整理します。
- 長文コンテキストは確かに革命的だが、企業ナレッジベース用途ではコスト・容量・権限・精度・更新の5つの壁がある: 「全部食わせれば済む」論は、個人利用や小規模文書群には当てはまるが、企業全体の文書には現時点では当てはまらない
- RAGと長文コンテキストは対立ではなく補完関係: ピンポイント検索型はRAG、全体俯瞰型は長文コンテキストが強い
- 現実解はハイブリッド型: Agentic RAG、RAG + Long Context、Cache-Augmented Generation など、両者を統合する設計が主流になりつつある
- 設計時の判断軸は5つ: 文書量、権限分離、更新頻度、コスト許容度、質問タイプ。自社の要件をこの5軸で整理すれば最適解が見えてくる
AI技術の進化は速く、数年後には今の常識がまた塗り替わっている可能性も十分にあります。それでも、「自社のユースケースに対してどの技術が最適か」を判断する視点 は、どんな時代でも変わらず重要です。本記事が、その判断の手がかりになれば幸いです。
関連記事
この記事をシェア
関連記事

RAGの限界とは?ハルシネーションを防ぐskillモードを実例で解説【2026年版】
RAGはなぜ「嘘の回答(ハルシネーション)」を起こすのか。複数文書の比較・大量ドキュメント・該当なし質問でつまずくRAGの構造的な限界と、ものしりAIがskillモード(Corpus2Skill)でどう解決したかを、人事規程の実例とともに解説します。

RAGとは何か?社内文書検索を劇的に変える仕組みをわかりやすく解説
RAG(検索拡張生成)の仕組みを非エンジニア向けに解説。従来の社内文書検索の限界と、RAGがもたらす変化、企業導入時の注意点までをまとめて紹介します。

「RAG不要論」は本当か?社内ナレッジAIの判断軸6つ
ロングコンテキストLLMの登場で「RAGはいらない」と言われる時代。本当に不要なケースと、依然としてRAGが必要なケースを6つの判断軸で整理し、社内ナレッジAI選びの実務指針を解説します。
