
編集部注: 本記事はRAG技術の一般解説です。ものしりAIはRAGを本番運用で検証した上で、現在は Corpus2Skill(skillモード)を採用しています。判断の経緯はこちら。
「生成AIを社内に導入したいが、自社の情報を踏まえて回答してほしい」。そんな声が急速に増えています。その鍵を握る技術が RAG(ラグ) です。
RAGは、生成AIに社内文書を"読ませながら"回答を作らせる仕組みで、最近のAI活用のほぼすべての基盤になっています。本記事では、RAGとは何かを非エンジニアの方にもわかるように解説し、なぜ社内文書検索を劇的に変えるのか、そして企業で導入する際に押さえておきたい注意点までをまとめて紹介します。
この記事で分かること
- RAG(Retrieval-Augmented Generation)の基本的な考え方
- 従来の社内文書検索の限界とRAGがもたらす変化
- RAGを構成する3つの部品(埋め込み・ベクトル検索・LLM)
- 企業でRAGを導入する際の注意点
RAGとは何か -- 生成AIに社内文書を"参照させる"仕組み
RAGは Retrieval-Augmented Generation(検索拡張生成) の略で、日本語では「検索拡張生成」と訳されます。ひとことで言えば、「AIに答えさせる前に、関連する情報を検索して読ませる」 という仕組みです。
生成AIは、学習済みの膨大な知識をもとに自然な文章を生成できますが、自社の社内文書は学習していません。そのため、何も工夫せずに「当社の有給休暇の取り方を教えて」と聞いても、一般論や誤った回答しか返せません。
RAGは、この問題を次のような流れで解決します。
- ユーザーの質問を受け取る
- 社内文書の中から、質問に関連しそうな部分を検索する
- 検索結果をAIに渡し、「この情報を参考に答えてください」と指示する
- AIが、渡された情報をもとに回答を生成する
この「検索してから生成する」という一手間が、生成AIを"自社のことを知っているAI"に変えるのです。

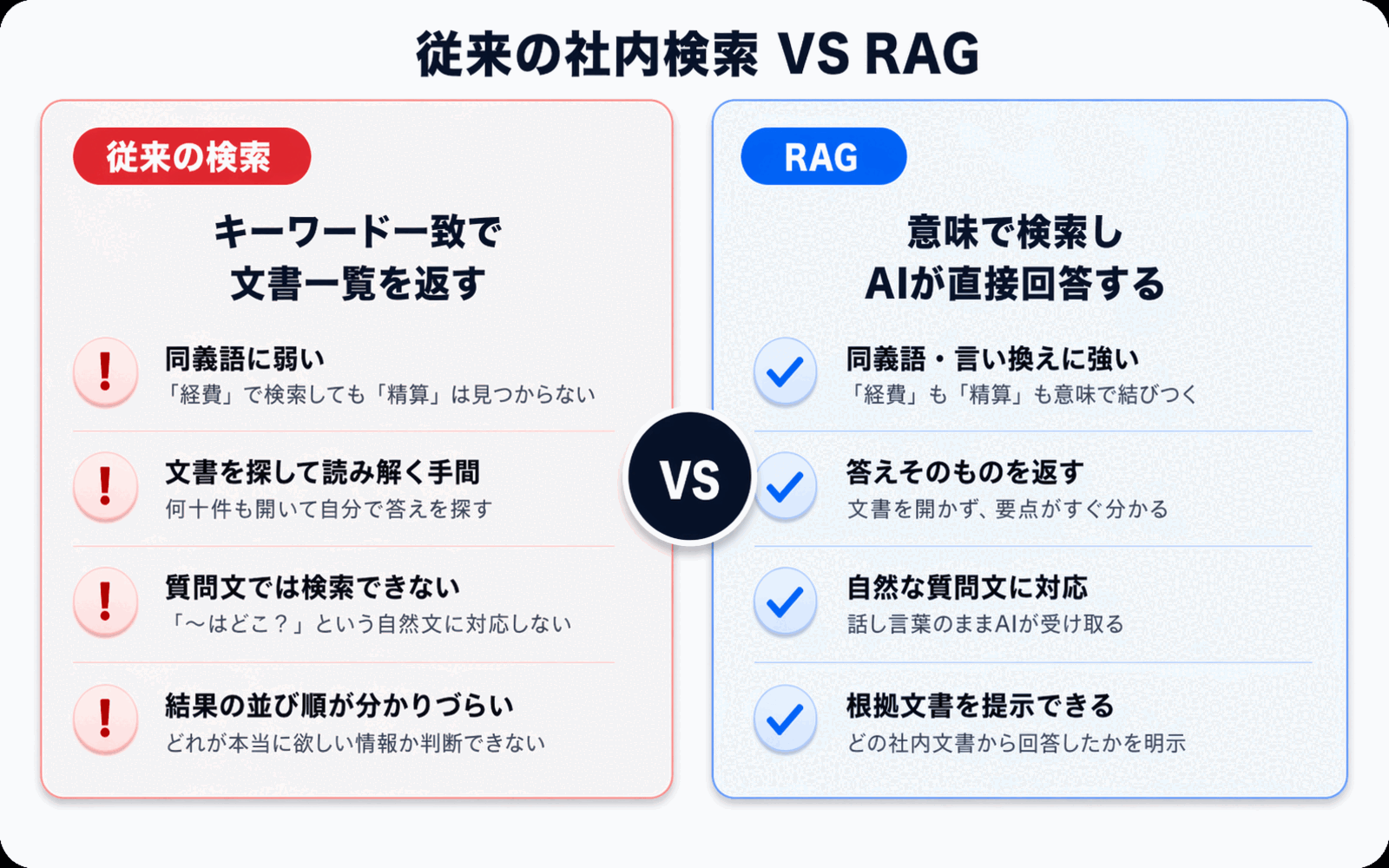
従来の社内文書検索は、なぜ使いづらいのか
RAGの価値を理解するために、まずは従来の社内文書検索を振り返ってみましょう。多くの企業で使われている検索は、大きく分けて2種類です。
1. キーワード検索
ファイルサーバーやグループウェアに搭載されている検索機能のほとんどは、入力した文字列と一致する単語を探すキーワード検索です。これには、次のような限界があります。
- 表記ゆれに弱い: 「有給」と検索しても、文書内が「年次休暇」と書かれていればヒットしない
- 同義語・言い換えに対応できない: 「経費精算」と「立替払い」が別物として扱われる
- 検索スキルに依存する: どの言葉を使えばヒットするかは、検索する人の勘と経験次第
2. 全文検索エンジン
ElasticsearchやOpenSearchなどの全文検索エンジンを導入すれば、キーワード検索よりは柔軟になります。しかし根本は文字列マッチに近く、複数の文書を横断して1つの答えにまとめることはできません。結局、ユーザーは検索結果のファイルを1つずつ開き、自分で答えを組み立てる必要があります。
つまり、従来の検索は 「文書を探すところまで」しかやってくれない のです。「答えを知りたいだけ」のユーザーにとっては、まだ手間が大きく残っています。
RAGがもたらす変化 -- 「検索」から「回答生成」へ
RAGの本質は、検索と生成AIを組み合わせることで、ユーザーの体験を「文書を探す」から「答えを受け取る」に変えたことにあります。
従来の検索とRAGを、同じ質問で比較してみましょう。
| 項目 | 従来のキーワード検索 | RAGを使ったAI回答 |
|---|---|---|
| 入力 | キーワード(単語) | 自然な文章での質問 |
| 出力 | ヒットしたファイル一覧 | 質問への直接的な回答 |
| 表記ゆれ | 弱い(同義語は別物扱い) | 強い(意味で検索する) |
| 複数文書の統合 | できない(個別に開く必要あり) | できる(横断して回答を生成) |
| 根拠の確認 | ファイルを開いて自分で探す | 回答と一緒に参照元が示される |
| 使える人 | 検索に慣れた人 | 新入社員を含む全員 |
特に大きいのは、「新入社員でも使える」 という点です。キーワード検索はコツを知らないと使いこなせませんが、AIへの質問は自然な言葉で話しかけるだけで済みます。社内情報への入口が、一気にフラットになります。
RAGの仕組みをもう少し詳しく -- 3つの部品
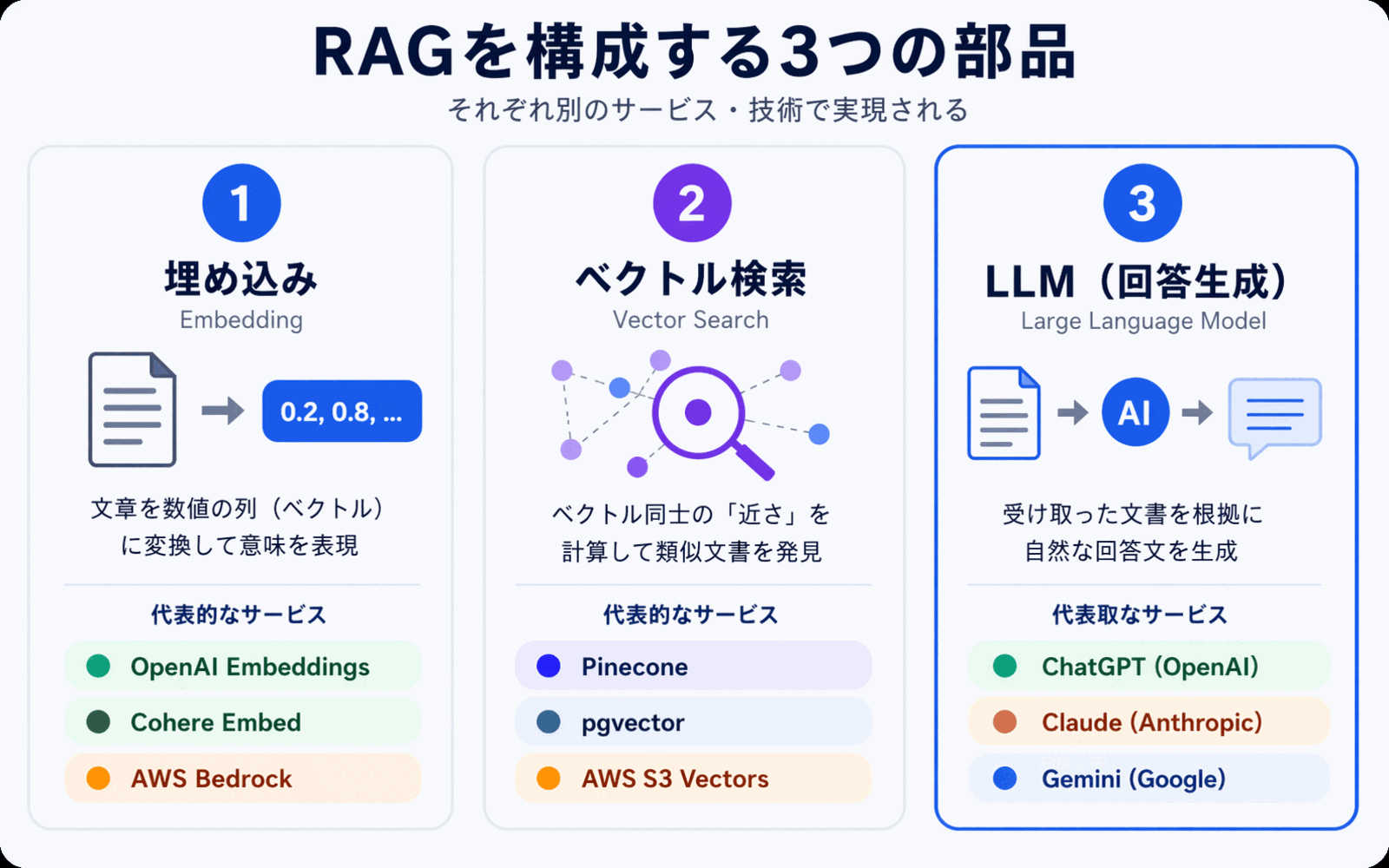
RAGは、大きく分けて 埋め込み(Embedding)、ベクトル検索、LLM(大規模言語モデル) という3つの部品で成り立っています。仕組みを知っておくと、導入時のツール選定でも迷わなくなります。
1. 埋め込み(Embedding) -- 文章を"数字の列"に変換する
埋め込みとは、文章の意味を 数百〜数千個の数字の並び(ベクトル) に変換する処理です。意味が近い文章は、変換後の数字の並びも近くなるように作られています。
たとえば「有給休暇の申請方法」と「年次休暇の取り方」は、文字としては違うのに、意味が近いので似た数字の並びに変換されます。これが、表記ゆれや同義語を吸収できる理由です。
社内文書をRAGに使う時は、まずすべての文書をこのベクトルに変換しておきます。この下準備のことを「インデックス化」と呼びます。
2. ベクトル検索 -- 意味が近いものを見つけ出す
質問が入ってきたら、質問文も同じ方法でベクトルに変換し、あらかじめ作っておいた社内文書のベクトルと比較して、意味が近いものを上位から取り出します。
これが「セマンティック検索(意味検索)」とも呼ばれる技術で、RAGの"検索パート"の中核になります。キーワードが一致していなくても、意味が近ければヒットするのが特徴です。
3. LLM -- 検索結果をもとに回答を生成する
最後に、取り出した社内文書の抜粋と、元のユーザーの質問をセットにしてLLM(大規模言語モデル)に渡します。LLMは、渡された情報を読みながら、「この資料に基づくと、有給休暇は原則として...」 のように、自然な文章で答えをまとめます。
ここで重要なのは、LLMは手元の資料を読みながら答えているという点です。自社の情報に即した回答になりやすく、根拠となった文書を一緒に提示することもできます。
セマンティック検索そのものの仕組みについては、セマンティック検索とは?社内文書をAIで探す仕組みで詳しく解説していますので、あわせてご覧ください。
企業でRAGを導入する時の注意点
RAGは強力な仕組みですが、導入すれば必ずうまくいくというものではありません。社内で定着させるためには、いくつか押さえておきたいポイントがあります。
1. データの置き場所とセキュリティを確認する
RAGは社内文書をAIに読ませる仕組みのため、文書データがどこに保管され、誰がアクセスできるのかを明確にする必要があります。海外リージョンに保存されると、コンプライアンス要件を満たせないケースもあります。
ツールを選ぶ際は、データの保存リージョン、暗号化の方式、テナント(組織)ごとの分離がどう実装されているかを確認しましょう。詳しくはセキュリティポリシーもあわせてご覧ください。
2. 根拠となる文書が示されることを重視する
生成AIの回答は自然な文章で返ってくる一方、一見もっともらしい間違い(ハルシネーション) を起こすことがあります。これを防ぐために、RAGで生成した回答には、根拠となった社内文書へのリンクや抜粋が一緒に表示されることが重要です。
ユーザーは回答をそのまま信じるのではなく、必要に応じて元の文書を確認できる状態にしておく。これがRAG運用の基本姿勢です。
3. 元のドキュメントの品質が回答品質を決める
RAGはあくまで 「社内にある情報をもとに答える」 仕組みです。元のドキュメントが古かったり、矛盾していたりすると、その矛盾がそのまま回答に現れます。
導入とあわせて、古い規程の整理、重複ドキュメントの統合、FAQの整備を進めることが、回答品質を高める近道になります。AIを入れることで、結果的にドキュメント整理のモチベーションが生まれる、という副次効果もあります。
4. コスト構造を把握する
RAGは、質問のたびに「ベクトル検索」と「LLM呼び出し」が走るため、利用量に応じてコストが発生する仕組みを採用しているサービスが一般的です。ユーザー数ではなく利用量で課金されるのか、定額で使い放題なのかは、サービスによって大きく違います。
社員全員に使ってもらいたい場合は、ユーザー数無制限か、十分な利用枠がある定額プランを選ぶと、コスト読みがしやすくなります。料金プランを比較検討する際の参考にしてください。
5. 使ってもらうための導線を設計する
どれだけ優れた仕組みを導入しても、社員が毎日使う場所に置かれていなければ定着しません。管理画面にログインしないと使えないツールは、使われないまま放置されがちです。
LINEやチャットウィジェットなど、普段の業務フローに溶け込む形でアクセスできることが定着の鍵になります。
補足: RAGとその次の選択肢
RAGは強力な仕組みですが、本番運用すると「チャンク化による出典の曖昧さ」「ベクトルインフラの常時コスト」「再ベクトル化の運用負荷」といった現実的な課題に直面することがあります。社内ナレッジをAIに聞けるものしりAI自身もRAGを本番運用したうえで、これらを解消するために Corpus2Skill(skillモード)への全面移行を行いました。判断の経緯はRAGをやめました -- ものしりAIがCorpus2Skill(skillモード)に全面移行した理由で、長文コンテキストを含む選択肢の整理はRAGはもう古い?長文コンテキスト時代のナレッジベース設計で解説しています。
まとめ
本記事では、RAG(検索拡張生成)の仕組みと、社内文書検索への活用についてお伝えしました。ポイントを整理します。
- RAGは「AIに答えさせる前に関連文書を検索して読ませる」仕組み: 生成AIが学習していない自社情報にも、正確に答えられるようになる
- 従来の検索との違いは「文書を探す」から「答えを受け取る」への変化: 表記ゆれや同義語に強く、複数文書を横断した回答を生成できる
- 仕組みは3つの部品に分かれる: 埋め込み・ベクトル検索・LLMの組み合わせで成立している
- 導入の成否は運用で決まる: データ保管・根拠明示・ドキュメント品質・コスト構造・定着導線の5点を押さえることが重要
RAGは、もはや一部の先進企業だけのものではなく、社内ナレッジを活用するうえでの標準的な手段になりつつあります。自社のどの業務から始めるか、どんなドキュメントを最初に載せるかを考えるところから、導入の検討を始めてみてはいかがでしょうか。
この記事をシェア
関連記事

RAGの限界とは?ハルシネーションを防ぐskillモードを実例で解説【2026年版】
RAGはなぜ「嘘の回答(ハルシネーション)」を起こすのか。複数文書の比較・大量ドキュメント・該当なし質問でつまずくRAGの構造的な限界と、ものしりAIがskillモード(Corpus2Skill)でどう解決したかを、人事規程の実例とともに解説します。

RAGはもう古い?長文コンテキスト時代のナレッジベース設計
1Mトークン対応の長文コンテキストで「RAG不要論」が浮上。コスト・権限・精度など5つの観点から、企業ナレッジベースにおける現時点の最適解を解説します。

セマンティック検索とは?社内文書をAIで探す仕組みと導入3ステップ
セマンティック検索(意味検索)とは何かを図解で解説。キーワード検索では見つからない社内文書をAIで探す仕組みと、非エンジニアでもできる導入3ステップを紹介します。
