
「AIに社内文書を答えさせたいが、嘘をついたらどうしよう」「複雑な質問になると検索が当たらない」。AIナレッジベースを検討中のお客様から最もよくいただく不安です。
ものしりAIも、サービス開始当初は他の多くのAIサービスと同じく RAG(Retrieval-Augmented Generation、検索拡張生成) を採用していました。しかし本番運用を続けるなかで、お客様の業務にとってRAGの構造的な限界が無視できないことに気づきました。そこで2026年4月、ものしりAIは skillモード(Corpus2Skill) という新しい仕組みに全面移行しました。
この記事では、なぜRAGだけでは答えきれない質問が出てくるのか、そして ものしりAIがskillモードでお客様に約束していること を、実際の利用シーンに沿って解説します。
この記事で分かること
- RAGがハルシネーション(嘘の回答)を起こす構造的な理由
- 大量のドキュメント、複数の項目をまたぐ質問でRAGが弱い理由
- ものしりAIがskillモードで解決した3つの課題
- 実際の社内ナレッジ用途で、RAGとskillモードの回答がどう違うか
1. なぜRAGは「嘘」をつくのか
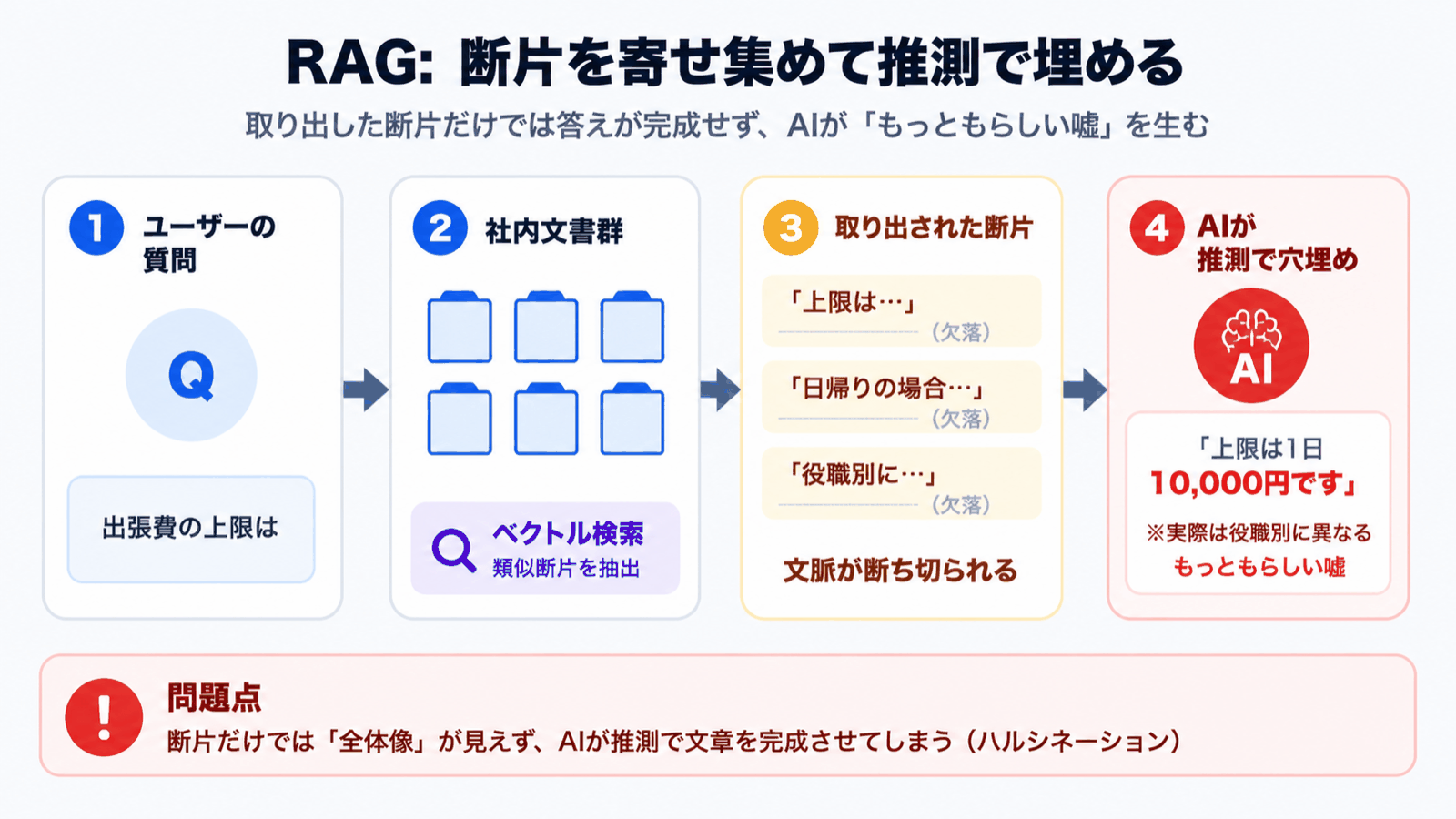
RAGの仕組みは、ざっくり次の流れで動きます。
- ドキュメントを細かい断片(チャンク)に分けて、ベクトル化しておく
- ユーザーの質問もベクトル化して、似た断片を 数件だけ 取り出す
- 取り出した断片をAIに渡して、回答を作らせる
シンプルで強力ですが、「数件だけ取り出す」「その範囲で答えさせる」 という設計が、ハルシネーションの温床になります。
よくある失敗パターン
- 質問に最も関連する断片が、検索結果のトップに出てこなかった → AIは「手元にある断片」だけで答えを作ろうとして、足りない部分を 推測で埋めてしまう
- 重要な情報がチャンクの境目で分断された → 表の見出しと数値、規程の前提条件と但し書きなどが別チャンクに分かれ、文脈ごと壊れた状態でAIに渡る
- 答えが「文書のどこにも書いていない」場合 → AIは検索結果を見て、それっぽい言い回しで作文してしまう
つまりRAGは 「検索結果の品質」がそのまま回答の品質を決める 仕組みです。検索が外れた瞬間、AIは平気で嘘をつきます。これがお客様の業務にとって致命的でした。
法務・人事・経理など「正確さ」が業務の前提になる部署では、AIの答えに自信を持って従えないというのは導入をためらう一番の理由です。
2. ものしりAIが直面した3つの限界
ものしりAIは、社内規程・マニュアル・FAQの活用を中心としたナレッジベースSaaSです。実際にRAGで本番運用するなかで、以下の3つの場面で限界に直面しました。
限界1. 複数の文書をまたいだ質問に答えられない
例えば次のような質問。
「就業規則と人事評価制度規程を比較して、評価面談の頻度がどう違うかまとめて」
これは2つの文書を 同時に読んで比較 しないと答えられません。しかしRAGは「質問に近い断片を数件取り出す」設計なので、片方の文書の断片だけ取って、もう片方は無視する ことがよく起こります。結果として「就業規則ではこう書いてあります」とだけ答えて、肝心の比較が成立しないか、最悪は 「人事評価制度規程ではこう書いてある」と勝手に作文してしまう ハルシネーションが発生します。
限界2. 大量ドキュメントから絞り込めない
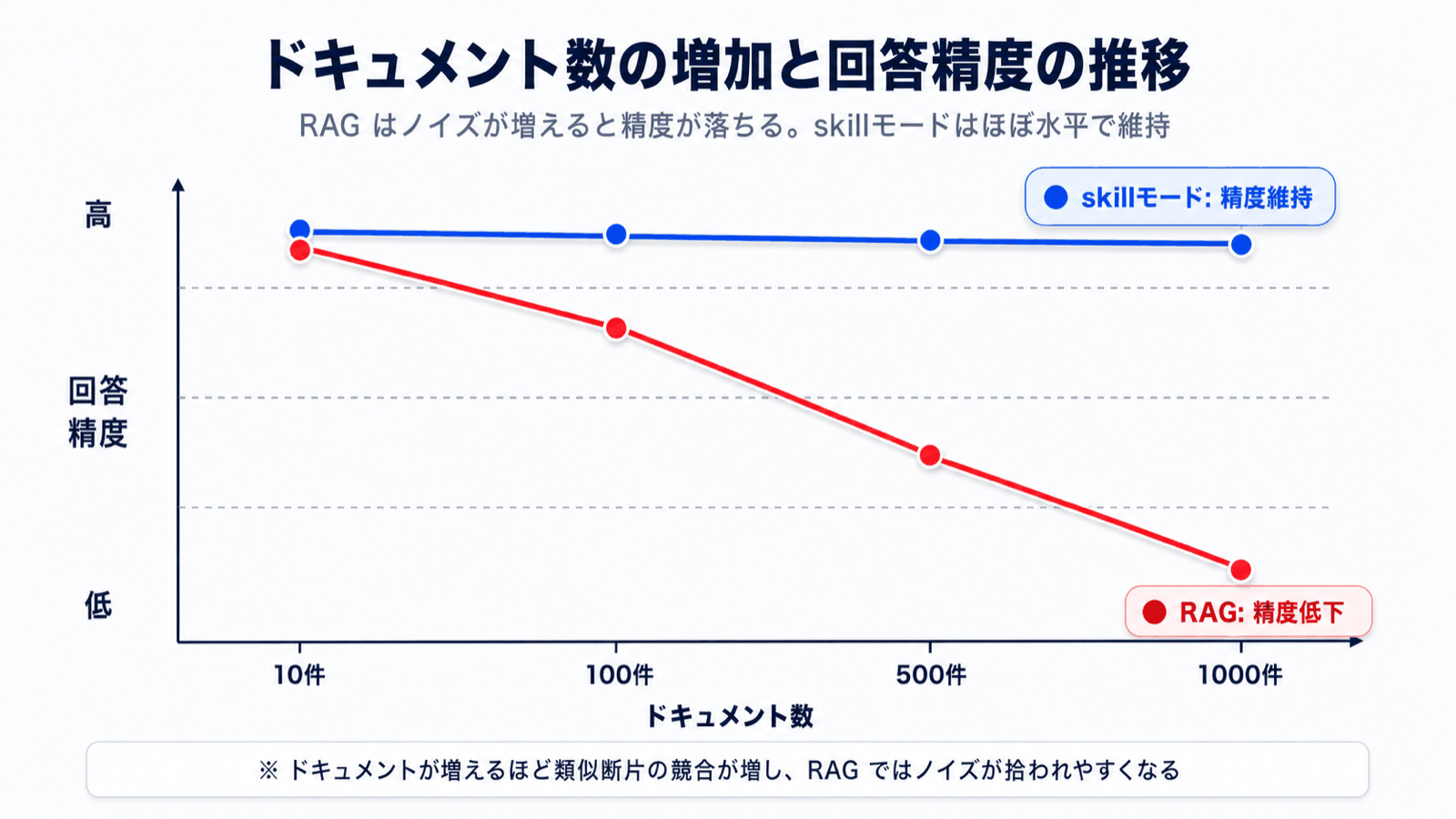
ナレッジが100件、300件と増えるにつれ、検索精度は確実に落ちていきます。なぜなら、
- ドキュメント数が増えると、似た言い回しの断片が複数の文書に散らばる
- 「関連スコアが似ている断片」が増え、本当に必要なものが埋もれる
- ユーザーの質問が抽象的だと、的外れな文書の断片が混ざりやすい
「ドキュメントをたくさん溜め込むほど、AIが鈍くなる」という逆説的な現象が起きるのです。社内ナレッジは時間とともに増えるものなので、これは運用の根本にかかわる問題でした。
限界3. 「情報がない」ことを正直に言えない
最後にして最も厄介なのが、「文書に書かれていない質問」への対応 です。
「APIキーの発行手順は?」(ナレッジに含まれていない情報の場合)
RAGは「最も近い断片を引っ張ってくる」仕組みなので、完全に無関係な情報でも何かしら出てきます。AIはそれを見て「APIキーは管理画面から発行できます」のような もっともらしい嘘 を返してしまいます。
「情報がないことを、情報がないと答えられない」というのは、業務利用では致命的です。
3. ものしりAIの答え: skillモード
これらの限界を乗り越えるために、ものしりAIが採用したのが skillモード(Corpus2Skill) です。
ひと言で説明すると、
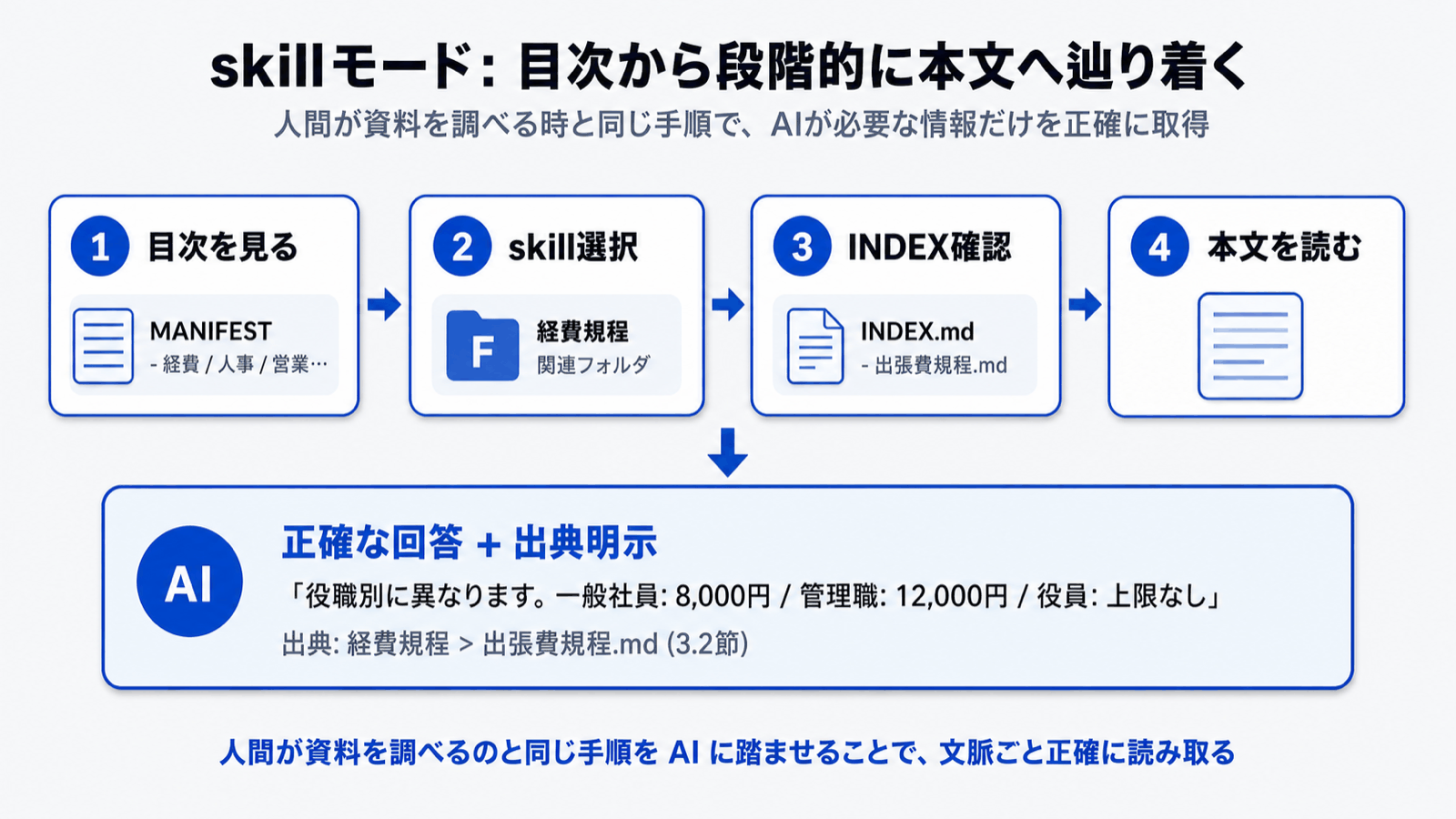
AIに「目次」を渡して、必要な文書を自分で読みに行かせる方式
です。RAGが「検索して、結果を渡す」のに対して、skillモードは「目次から辿って、本文を読む」という、人間と同じプロセスでナレッジを参照します。
お客様視点で何が変わるか
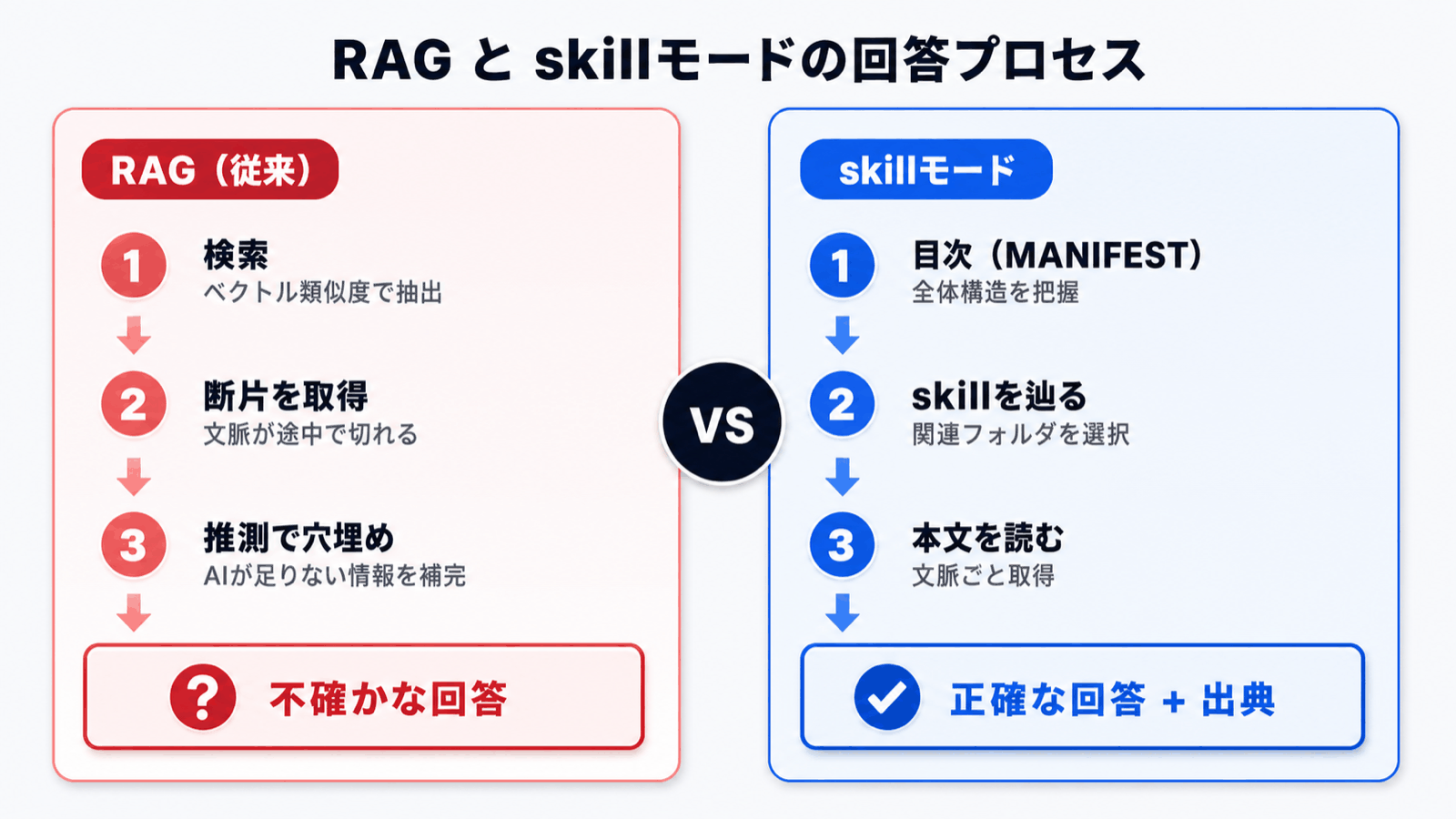
| 観点 | RAG | skillモード |
|---|---|---|
| 答えの根拠 | 検索された断片(数件) | AIが実際に読んだ文書全体 |
| 嘘をつくリスク | 検索が外れると作文する | 「該当文書なし」と答えられる |
| 複数文書の比較 | 苦手 | 必要な文書を順に読みに行く |
| 大量ドキュメント | 増えるほど精度劣化 | 目次から絞り込むので影響少ない |
| 出典の明示 | スコア付きの断片 | 「○○規程の○ページを参照しました」と具体的に提示 |
skillモードは、「答えにたどり着くまでにどの文書を読んだか」がそのまま履歴として残る ため、ユーザーは「AIがどう考えたか」を後から検証できます。これが業務利用では非常に大きな安心感につながります。
4. 実際の利用シーンで何が違うか
具体例で見てみましょう。社内に「就業規則」「人事評価制度規程」「ハラスメント対応マニュアル」「給与・賞与・退職金規程」など20件の人事系規程が格納されているケースです。
シーン1: 「評価面談の頻度を、就業規則と人事評価制度規程で比較して」
- RAGの場合: 「就業規則」の断片だけ取れて、「年1回」と回答。人事評価制度規程の断片が取れず、比較が成立しない。最悪、勝手に「人事評価制度規程では半年に1回」と作文する
- skillモードの場合: AIが目次から「就業規則」「人事評価制度規程」を両方選び、それぞれの該当箇所を読んだうえで「就業規則では年1回、人事評価制度規程では四半期ごとと記載されています」と正確に回答
シーン2: 「育児休業から復帰する際の流れを教えて」
- RAGの場合: 「育児休業」というキーワードを含む断片を集めるが、復帰後の手続きや評価への影響など複数規程にまたがる情報を統合できず、片面的な回答になりがち
- skillモードの場合: 「育児休業」関連の規程を複数読み、復帰前の手続き → 復帰時の業務調整 → 復帰後の評価への影響、と 時系列に整理された回答 を返す
シーン3: 「APIキーの発行方法は?」(該当文書なし)
- RAGの場合: 関連性の低い文書から無理やり断片を持ってきて、それっぽい手順を作文してしまう
- skillモードの場合: 目次を確認してから「この情報は登録されているドキュメントには含まれていません」と明言。担当者へ問い合わせるよう促す
業務として安心して使えるのは、明らかに後者です。
5. なぜ「目次から辿る」方式が業務ナレッジに合うのか
社内ナレッジには、Webページのような無秩序な情報の集積とは違う特徴があります。
- 構造化されている: 規程は章立て、マニュアルは手順、FAQはカテゴリで整理されている
- 更新の単位が文書: 規程改定は「文書まるごと差し替え」が基本
- 正確さが業務に直結: 法務・人事・経理は誤解で重大な問題が起きる
これらの特徴は RAGよりも「目次から辿る」方式のほうが圧倒的に相性が良い のです。
ものしりAIはこの相性を最大限に活かす設計に振り切りました。お客様がフォルダにドキュメントを入れると、AIが自動で 意味的なグルーピングと目次 を構築し、質問が来るたびに目次から辿って必要な文書を読みに行きます。お客様が新しい文書を追加したり差し替えたりすると、目次も自動で更新されるため、運用コストもRAGと比べて格段に下がります。
6. ものしりAIがお客様にお約束していること
skillモードへの移行を機に、ものしりAIは次の3つをお客様にお約束しています。
1. 「分からない」は、はっきり「分からない」と答える
ナレッジに書かれていない質問には、もっともらしい作文ではなく、明確に「該当する記載がありません」 と返します。業務上の判断ミスを防ぐための、最も大事な原則です。
2. 出典は必ず明示する
AIの回答には、「どの文書のどの部分を読んで答えたか」 が必ず添付されます。回答を読んだ人が 元の文書をすぐ確認できる よう、出典は具体的なファイル名・該当箇所まで示します。
3. ドキュメントが増えても、精度を維持する
社内ナレッジは時間とともに必ず増えます。skillモードは目次から絞り込む構造のため、ドキュメントが100件、500件、1000件と増えても回答精度が安定 します。「最初は答えてくれたのに、文書を増やしたら鈍くなった」が起こりません。
まとめ -- AIナレッジは「速さ」より「正確さ」
ChatGPTやClaudeのような汎用AIが普及したことで、「AIに何でも聞ける」という期待が高まっています。しかし業務で使うナレッジAIに求められるのは、汎用AIの 流暢な回答 ではなく、自社の文書に根ざした正確な回答 です。
ものしりAIは、その「正確さ」を技術選定の最優先軸に置いた結果、RAGよりもskillモードのほうがお客様の業務に合う と判断しました。
「AIが嘘をつくのが怖くて、社内ナレッジに導入できない」と感じている方こそ、ぜひ一度、skillモードの回答品質をご体験ください。
関連記事
- RAGとは何か?社内文書検索を劇的に変える仕組みをわかりやすく解説
- RAGはもう古い?長文コンテキスト時代のナレッジベース設計
- 社内文書をAIで検索する方法 -- キーワード検索との違いと導入ステップ
技術判断の詳細を知りたい方へ: skillモード移行の技術的な背景・実装の話は、開発者個人のQiita記事 (RAG をやめました -- ナレッジAI SaaS「ものしりAI」 が Corpus2Skill (skill モード) に全面移行した理由) でより詳しく書いています。
この記事をシェア
関連記事

RAGとは何か?社内文書検索を劇的に変える仕組みをわかりやすく解説
RAG(検索拡張生成)の仕組みを非エンジニア向けに解説。従来の社内文書検索の限界と、RAGがもたらす変化、企業導入時の注意点までをまとめて紹介します。

RAGはもう古い?長文コンテキスト時代のナレッジベース設計
1Mトークン対応の長文コンテキストで「RAG不要論」が浮上。コスト・権限・精度など5つの観点から、企業ナレッジベースにおける現時点の最適解を解説します。

「RAG不要論」は本当か?社内ナレッジAIの判断軸6つ
ロングコンテキストLLMの登場で「RAGはいらない」と言われる時代。本当に不要なケースと、依然としてRAGが必要なケースを6つの判断軸で整理し、社内ナレッジAI選びの実務指針を解説します。
ものしりAIを無料で試してみませんか?
ドキュメントをアップロードするだけで、AIに質問できる環境が作れます。ユーザー数無制限の無料プランで、まずはお試しください。
無料で始めるクレジットカード不要 / 最短1分で利用開始