
编辑部注: 本文是关于RAG技术的通用解读。Monoshiri AI在生产环境中验证过RAG,目前已采用Corpus2Skill(skill模式)。决策经过见这里。
"想在公司内部引入生成式AI,但希望它能基于我们自己的资料来回答问题。"这样的声音正在迅速增多。实现这一目标的关键技术,就是RAG。
RAG是一种让生成式AI"一边读企业文档一边回答"的机制,目前几乎已成为所有AI应用的底层基础。本文将以非技术人员也能理解的方式,讲解RAG是什么、为什么它能彻底改变企业文档搜索,以及企业部署时需要注意的要点。
本文要点
- RAG(Retrieval-Augmented Generation)的基本理念
- 传统企业文档搜索的局限与RAG带来的变化
- 构成RAG的三大组件(嵌入、向量搜索、LLM)
- 企业部署RAG时需要注意的要点
什么是RAG -- 让生成式AI"参考"企业文档的机制
RAG是**Retrieval-Augmented Generation(检索增强生成)的缩写。用一句话概括,它是"在让AI回答之前,先检索相关信息并交给AI阅读"**的机制。
生成式AI可以基于庞大的训练数据生成自然流畅的文字,但它并没有学习过你公司的内部文档。因此,直接问"公司的年假申请流程是什么?",它只能给出一般性甚至错误的回答。
RAG通过以下流程解决这一问题:
- 接收用户的提问
- 从企业文档中检索与问题相关的内容
- 将检索结果交给AI,并指示"请参考这些信息进行回答"
- AI基于接收到的信息生成回答
"先检索,再生成"这一关键步骤,将通用生成式AI转变为真正了解贵公司的AI。

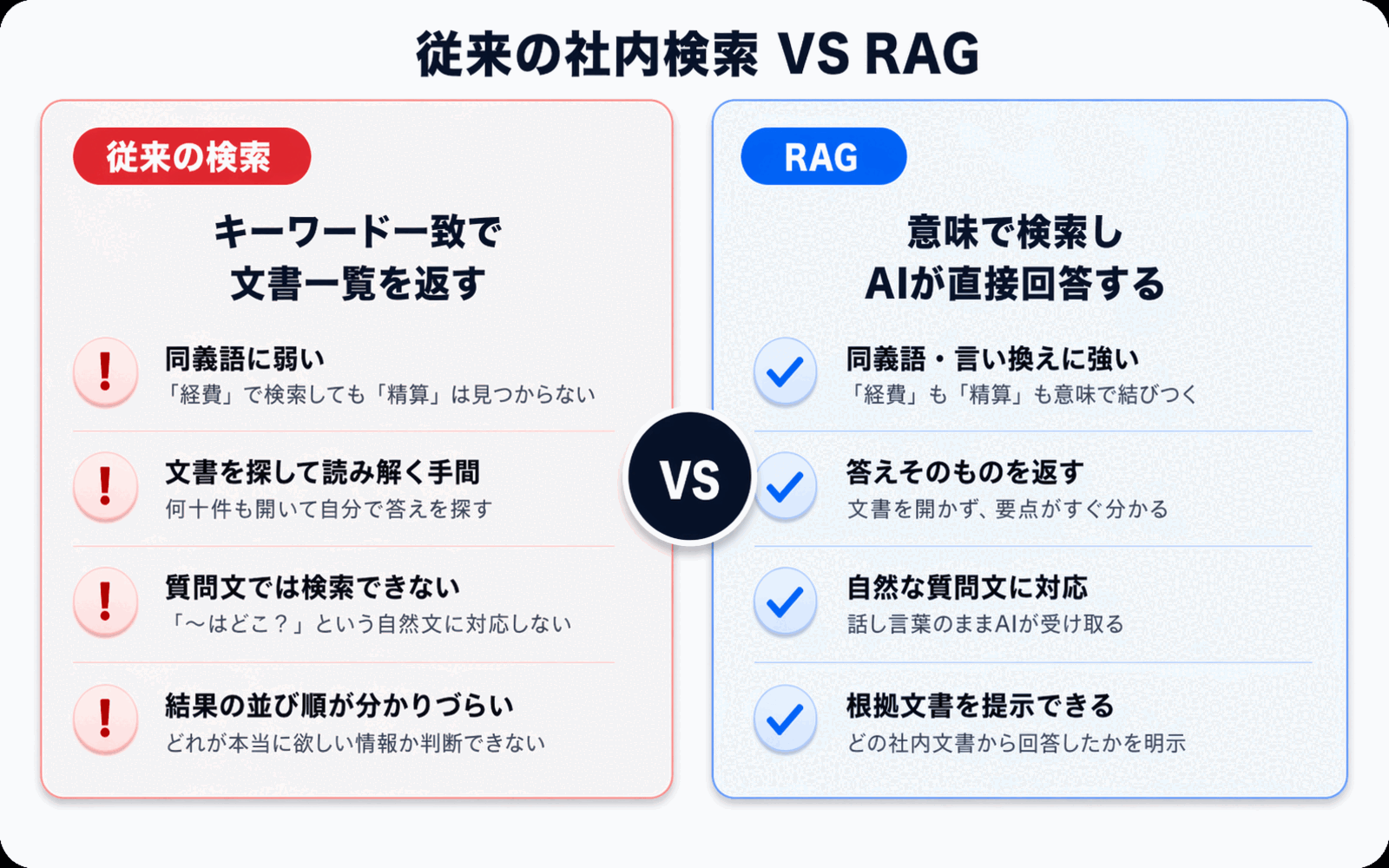
传统企业文档搜索为什么不好用
要理解RAG的价值,我们先回顾一下传统的企业文档搜索。目前大多数企业使用的搜索方式,大致分为两类。
1. 关键词搜索
文件服务器或协同办公平台内置的搜索功能,几乎都是查找与输入字符串完全匹配的词语的"关键词搜索"。这种方式存在以下局限:
- 难以应对措辞差异:搜索"年假"时,如果文档中写的是"年休假",就搜不到
- 无法处理同义词和近义词:"费用报销"和"垫付款"被当作完全不同的内容
- 依赖搜索技巧:用什么词能搜到,取决于搜索者的直觉和经验
2. 全文搜索引擎
引入Elasticsearch、OpenSearch等全文搜索引擎,可以比关键词搜索更灵活一些。但本质上仍接近字符串匹配,无法跨多个文档整合出一个完整答案。最终用户还是需要逐一打开搜索结果,自己整理答案。
也就是说,传统搜索只能帮你"找到文档"。对于"只想要答案"的用户来说,剩下的工作依然不少。
RAG带来的变化 -- 从"搜索"到"生成回答"
RAG的本质在于,通过将搜索与生成式AI结合,把用户体验从"查找文档"转变为"直接获得答案"。
我们用同一个问题对比一下传统搜索和RAG。
| 对比项 | 传统关键词搜索 | 使用RAG的AI回答 |
|---|---|---|
| 输入 | 关键词(单词) | 自然语言提问 |
| 输出 | 命中的文件列表 | 对问题的直接回答 |
| 措辞差异 | 不擅长(同义词被区别对待) | 擅长(基于语义检索) |
| 多文档整合 | 无法(需单独打开) | 可以(跨文档生成回答) |
| 依据确认 | 需要打开文件自行查找 | 回答的同时提供引用来源 |
| 适用人群 | 熟悉搜索的人 | 包括新员工在内的所有人 |
其中最大的意义在于,新员工也能轻松使用。关键词搜索需要掌握技巧才能用好,而向AI提问只需要用自然语言交流即可。企业内部信息的获取门槛一下子被拉平。
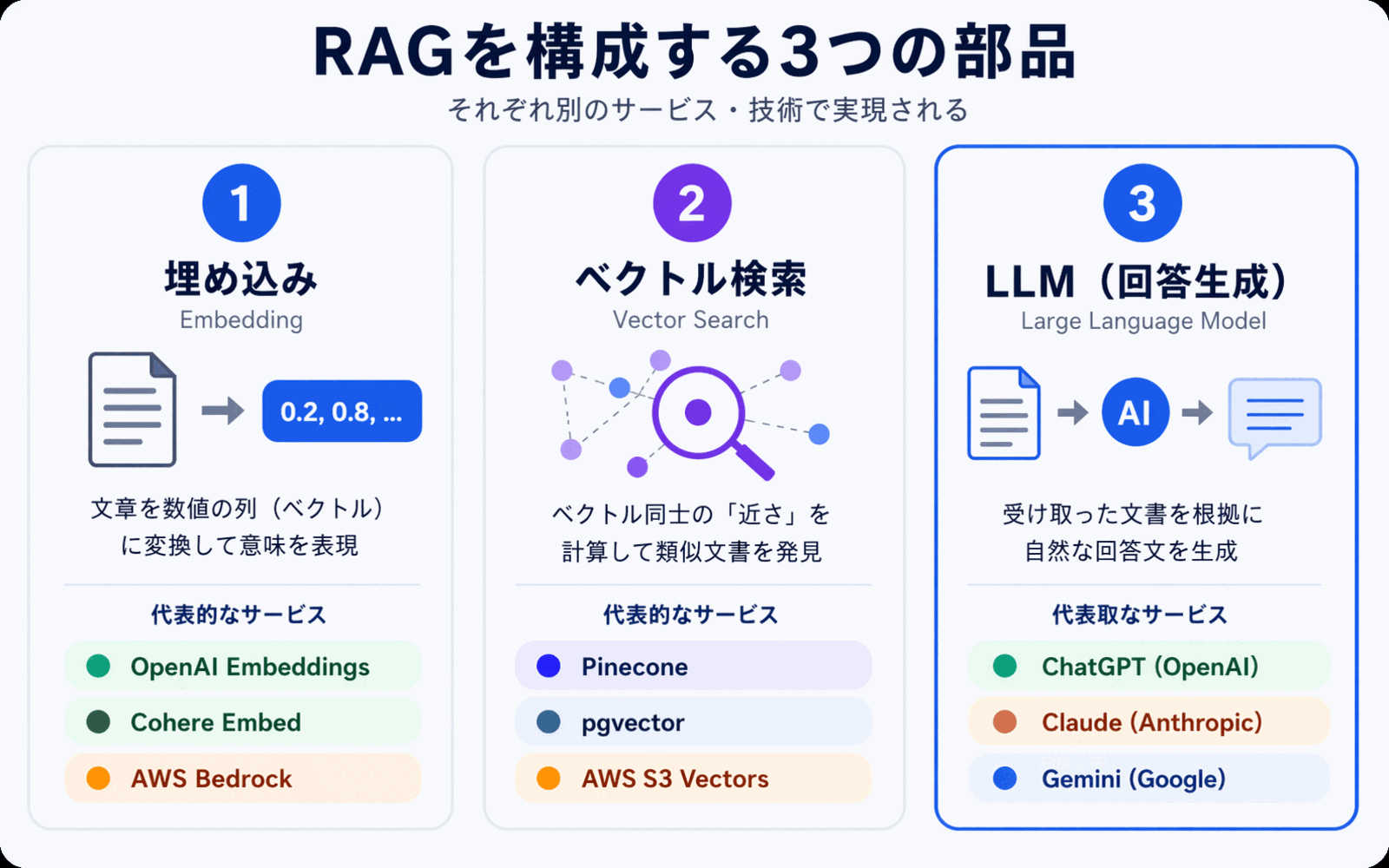
更详细地了解RAG的原理 -- 三大组件
RAG主要由嵌入(Embedding)、向量搜索、**LLM(大语言模型)**这三大组件构成。了解这套原理,在部署时选型也不会感到迷茫。
1. 嵌入(Embedding) -- 把文本转换为"数字序列"
嵌入是将文本的含义转换为**由数百到数千个数字组成的序列(向量)**的处理过程。设计上,语义相近的文本,其转换后的数字序列也会相近。
例如"年假申请方式"和"年休假怎么请",虽然字符不同,但语义相近,因此会被转换为相似的数字序列。这正是RAG能够处理措辞差异和同义词的原因所在。
在将企业文档用于RAG时,首先要将所有文档都转换为向量。这一准备工作称为**"索引化"**。
2. 向量搜索 -- 找出语义相近的内容
当问题输入时,提问文本也会以同样方式转换为向量,与预先构建的企业文档向量进行比对,将语义最接近的内容从上到下依次提取出来。
这就是被称为**"语义搜索(Semantic Search)"**的技术,也是RAG中"检索部分"的核心。即使关键词不一致,只要语义相近,也能被命中。
3. LLM -- 基于检索结果生成回答
最后,将提取出的企业文档摘录与用户的原始提问一并交给LLM(大语言模型)。LLM会一边阅读这些信息,一边用自然语言组织回答,例如**"根据该资料,年假原则上……"**。
这里的关键在于,LLM是在"阅读手头资料"的状态下作答的。它能紧贴贵公司的实际情况进行回答,并可同时标注出作为依据的文档。
关于语义搜索本身的原理,已在用AI搜索企业内部文档的方法一文中详细说明,欢迎一并阅读。
企业部署RAG时的注意事项
RAG虽然是强大的机制,但并不是部署了就一定能成功。要在企业内部真正落地,以下几个要点必须提前把握。
1. 确认数据存放位置与安全性
RAG的机制是让AI阅读企业内部文档,因此必须明确文档数据保存在哪里、由谁可以访问。如果数据被存储在海外区域,可能无法满足某些合规要求。
选择工具时,请确认数据保存区域、加密方式,以及组织(租户)之间的隔离是如何实现的。详情可参阅安全策略。
2. 重视回答中给出依据文档
生成式AI的回答自然流畅,但也可能出现**"看似合理却并非事实"的错误(幻觉)。为避免这一问题,RAG生成的回答中一定要同时展示作为依据的企业文档链接或摘录**。
用户不能全盘相信AI的回答,而应能够在必要时查看原始文档。这是运营RAG的基本态度。
3. 源文档的质量决定回答的质量
RAG本质上是**"基于企业内部已有信息进行回答"**的机制。如果源文档过时或存在矛盾,这些问题会原封不动地反映在回答中。
在部署的同时,推进整理过时规章、合并重复文档、完善FAQ,是提升回答质量的捷径。引入AI带来的一个附加效果是:它反过来会激发员工整理文档的动力。
4. 把握成本结构
RAG每次回答问题时都会触发"向量搜索"和"LLM调用",因此大多数服务采用按使用量计费的模式。按用户数计费,还是定额不限量,不同服务差别很大。
如果希望全体员工都能使用,选择不限用户数、或使用额度充足的定额套餐,可以让成本更易预估。定价方案可以作为对比选型的参考。
5. 设计使用触点,让员工真正用起来
再好的机制,如果不出现在员工每天都会接触的地方,也难以落地。只能在管理后台登录后才能使用的工具,往往最终无人问津。
LINE、聊天组件等能融入日常业务流程的接入方式,才是落地的关键。
补充:RAG与下一种选择
RAG是强大的机制,但生产化后可能会浮现"分块导致出处模糊""向量基础设施的固定成本""重新向量化的运维负担"等现实问题。可用 AI 查询企业内部知识的 Monoshiri AI自身在生产环境中实测了RAG之后,为解决这些问题全面迁移到了Corpus2Skill(skill模式)。决策的经过见我们放弃了RAG -- Monoshiri AI全面迁移到Corpus2Skill(skill模式)的原因,包括长文本上下文在内的更广泛选项整理见RAG已经过时了吗?长文本上下文时代的知识库设计。
总结
本文向您介绍了RAG(检索增强生成)的工作原理,以及它在企业文档搜索中的应用。要点整理如下:
- RAG是"先检索相关文档再让AI作答"的机制:即使是生成式AI未学习过的企业内部信息,也能准确作答
- 与传统搜索的区别在于从"查找文档"到"获得答案"的转变:能够应对措辞差异和同义词,跨多个文档生成回答
- 机制由三大组件构成:嵌入、向量搜索、LLM的组合协同工作
- 部署成败取决于运营:数据存放、依据展示、文档质量、成本结构、使用触点这五点尤为关键
RAG已不再是少数先进企业的专属技术,而正在成为利用企业内部知识的标准手段。不妨先从"从哪个业务开始"、"先上传哪些文档"入手,正式启动RAG的部署思考。
分享这篇文章
相关文章

「RAG 不需要」是真的吗?企业知识 AI 选型的 6 个判断维度
随着长文本上下文 LLM 的出现,「RAG 不需要」的论调越来越多。本文用 6 个判断维度梳理真正不需要的场景与依然需要 RAG 的场景,为企业知识 AI 选型提供务实指南。

什么是 Corpus2Skill?RAG 与 skill 模式的区别详解
「担心 AI 胡编乱造」「复杂问题无法回答」。本文以实际案例解析 RAG 的幻觉问题与检索精度局限,以及 Monoshiri AI 如何通过 skill 模式加以解决。

RAG已经过时了吗?长文本上下文时代的知识库设计
随着1M token级长文本上下文的普及,"RAG不再需要"的声音开始出现。本文从成本、权限、精度等五个维度,解析企业知识库当前的最优解。
