
「想让 AI 回答企业内部文档相关的问题,但万一它胡编乱造怎么办?」「问题一复杂,检索就完全跑偏。」这是我们从评估 AI 知识库的客户那里最常听到的担忧。
Monoshiri AI 在服务初期也和许多其他 AI 服务一样,采用了 RAG(Retrieval-Augmented Generation,检索增强生成)。然而在生产环境中持续运行后,我们意识到 RAG 的结构性局限对客户的实际业务来说已经不可忽视。因此在 2026 年 4 月,Monoshiri AI 全面切换到了被称为 skill 模式(Corpus2Skill) 的全新机制。
本文将结合实际使用场景,说明为什么仅靠 RAG 无法回答某些问题,以及 Monoshiri AI 通过 skill 模式向客户做出的承诺。
本文要点
- RAG 产生幻觉(虚假回答)的结构性原因
- RAG 在大量文档、跨多个项目的问题上表现薄弱的原因
- Monoshiri AI 通过 skill 模式解决的三大问题
- 在企业知识库的实际场景下,RAG 与 skill 模式的回答有何不同
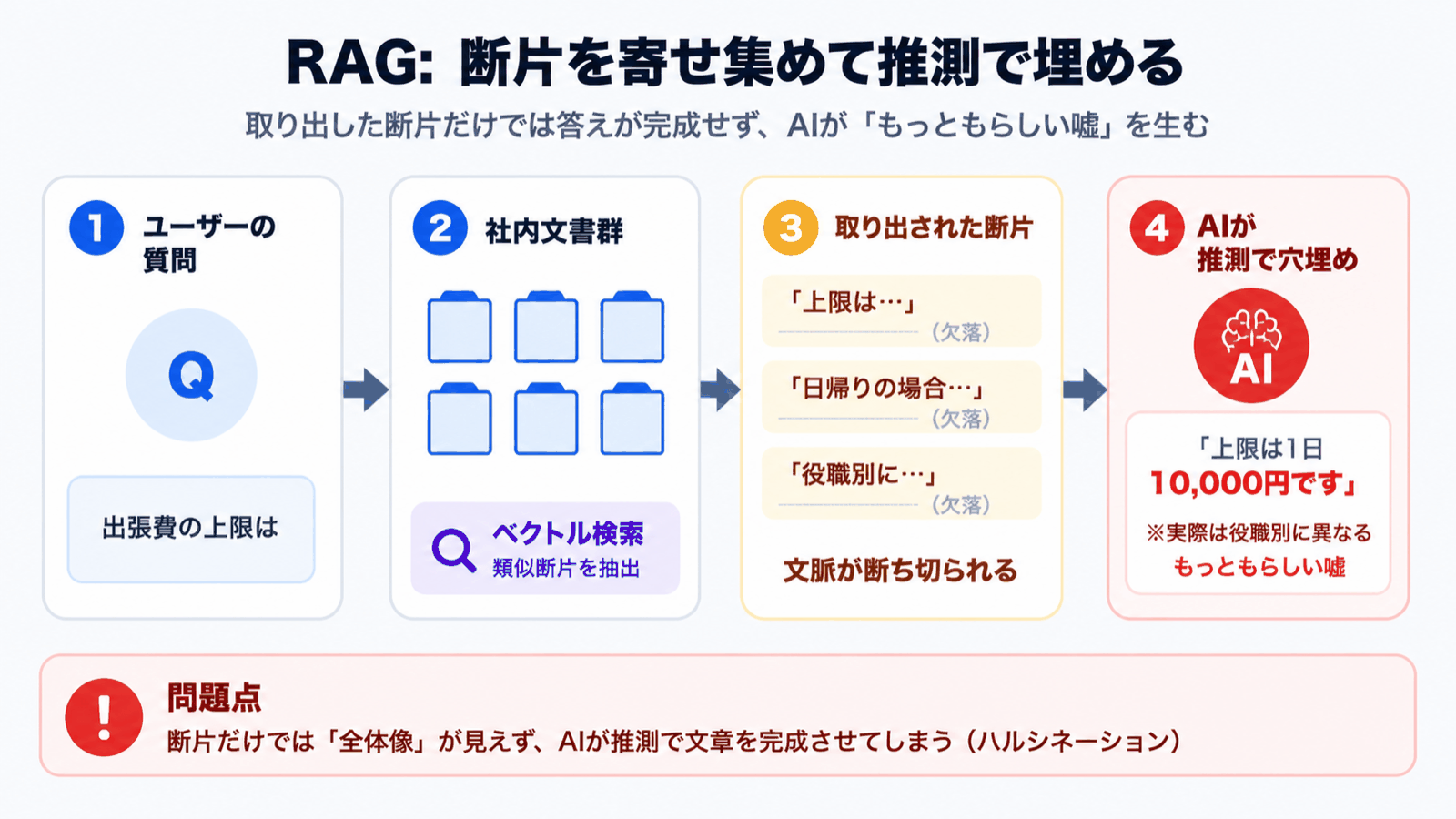
1. 为什么 RAG 会「撒谎」
RAG 的工作机制大致如下:
- 将文档切分为细小片段(chunk),并预先向量化
- 将用户的提问也向量化,仅取出几条最相似的片段
- 把这些片段交给 AI,让其据此生成回答
设计简单且强大,但「只取出少数几条」「仅在该范围内作答」的机制,正是幻觉滋生的温床。
常见的失败模式
- 与提问最相关的片段没有出现在检索结果的最上方 —— AI 只能基于「手头的片段」作答,用推测填补缺失的部分
- 关键信息在片段切分时被截断 —— 表头与数值、规章的前提条件与但书等被分到不同片段,AI 拿到的是已经断裂的上下文
- 答案根本就不在文档中 —— AI 看着检索结果,会用看似可信的措辞编造内容
也就是说,RAG 是一个**「检索结果质量直接决定回答质量」**的机制。一旦检索失误,AI 就会毫不犹豫地撒谎。这对客户的业务来说是致命的。
在法务、人事、财务等以正确性为业务前提的部门,「无法对 AI 的回答放心采信」正是阻碍引入的最大原因。
2. Monoshiri AI 面临的三大局限
Monoshiri AI 是一款以企业内部规章、操作手册、FAQ 应用为核心的知识库 SaaS。在 RAG 的实际运行中,我们在以下三个场景遇到了瓶颈。
局限 1. 无法回答跨多个文档的问题
例如这样的提问:
「比较《劳动规则》与《人事考核制度规章》,说明评估面谈频率有何不同。」
这需要同时阅读两份文档进行对比才能回答。但 RAG 的设计是「取出与问题最接近的几条片段」,因此经常出现只取了其中一份文档的片段,完全忽略另一份的情况。结果要么只能回答其中一边、对比无从成立,要么更糟——AI 擅自编造「《人事考核制度规章》中规定为半年一次」 这样的幻觉。
局限 2. 无法从大量文档中精确筛选
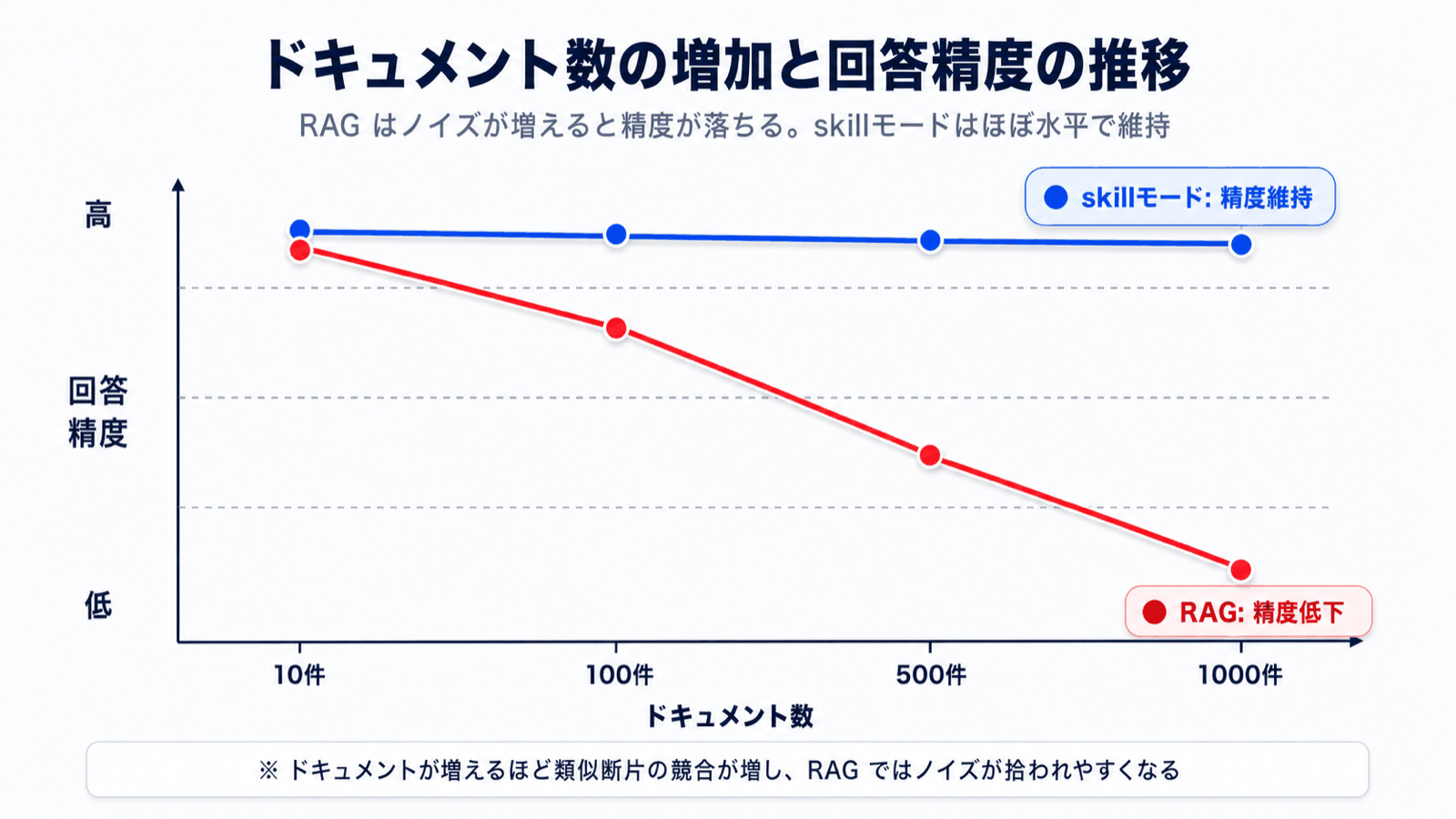
随着知识库累积到 100 件、300 件,检索精度必然下降。原因在于:
- 文档增多后,相似措辞的片段会散落在多份文档中
- 「相关度评分接近的片段」越来越多,真正需要的内容反而被淹没
- 用户提问越抽象,越容易混入与目标无关的文档片段
于是出现了一个悖论:「文档累积越多,AI 反而越迟钝」。企业内部知识本就会随着时间不断增加,这是关乎运营根本的问题。
局限 3. 无法老老实实地说「没有信息」
最棘手的是应对「文档中并未记载的提问」。
「API 密钥的发行步骤是什么?」(知识库中并不包含相关信息时)
由于 RAG 是「拉取最接近的片段」的机制,即使是完全无关的内容,也总会返回一些东西。AI 看到这些后,会回答出听起来很合理的谎话,例如「API 密钥可以在管理后台发行」。
「无法将『没有信息』如实告知用户」 在业务使用中是致命缺陷。
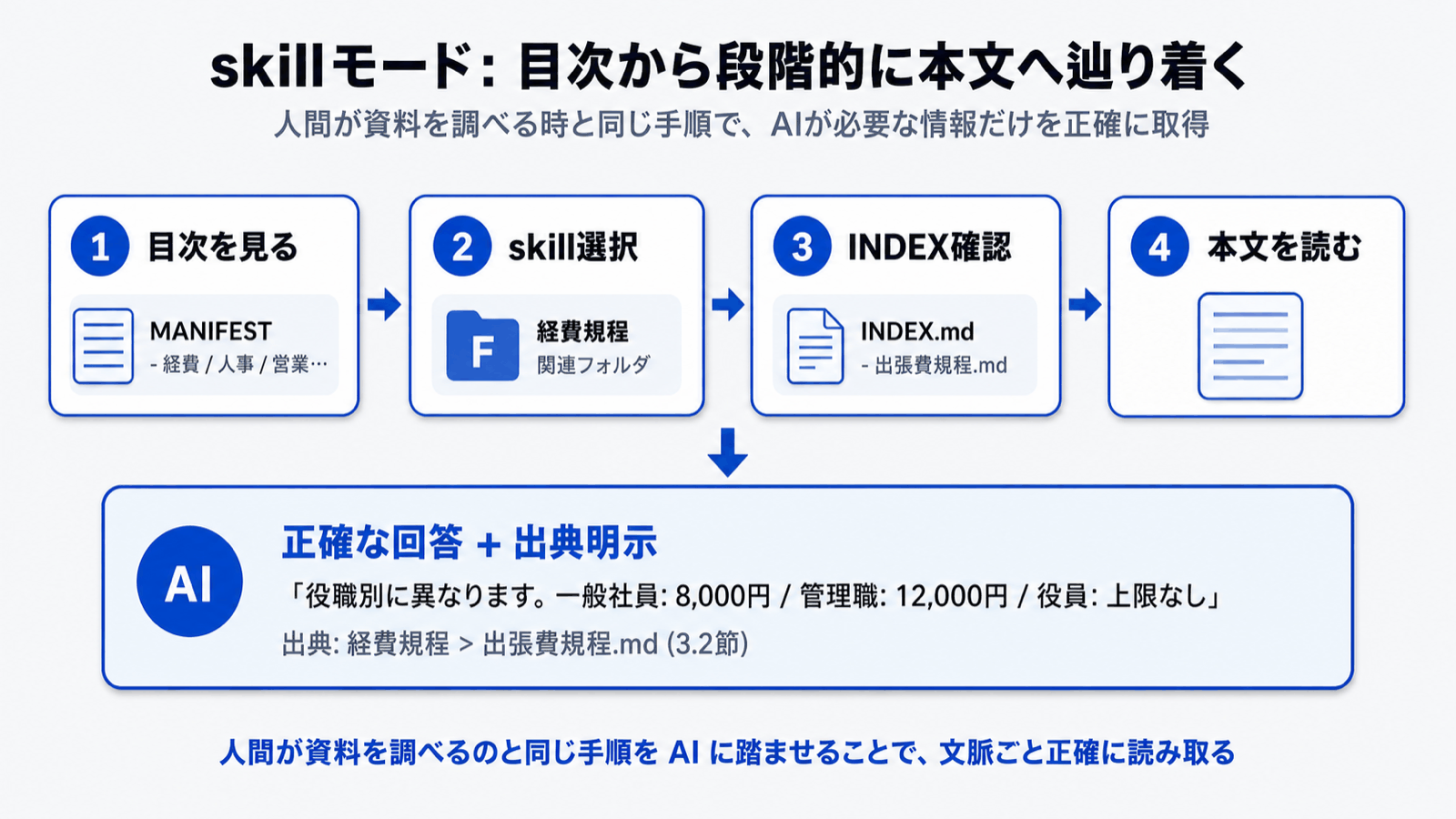
3. Monoshiri AI 的答案:skill 模式
为突破上述局限,Monoshiri AI 采用了 skill 模式(Corpus2Skill)。
一句话概括:
将「目录」交给 AI,让它自己去查阅所需文档的方式。
如果说 RAG 是「先检索,再把结果交给 AI」,那么 skill 模式就是「从目录顺藤摸瓜,再阅读正文」——这与人类查阅参考资料的过程完全一致。
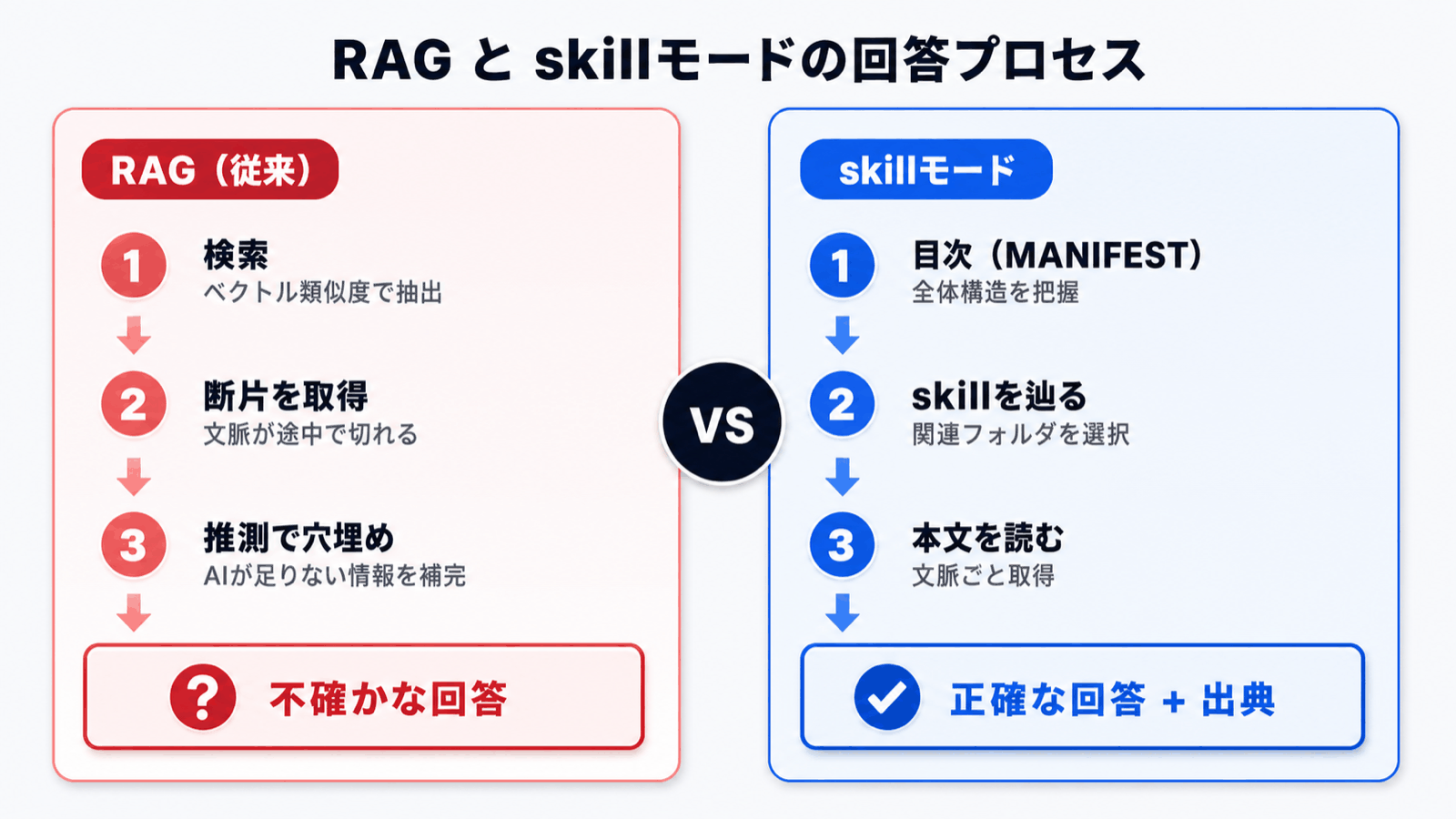
从客户视角看有何变化
| 视角 | RAG | skill 模式 |
|---|---|---|
| 回答的依据 | 检索到的若干片段 | AI 实际阅读过的完整文档 |
| 撒谎风险 | 检索失误就会编造 | 可以回答「未找到对应文档」 |
| 多文档比较 | 不擅长 | 按顺序阅读所需文档 |
| 大量文档 | 越多越掉精度 | 由目录筛选,影响很小 |
| 出处标注 | 带评分的片段 | 「参考了某规章第 X 页」等具体提示 |
skill 模式会完整保留「为得到答案阅读了哪些文档」的轨迹,用户事后可以验证「AI 是怎么思考的」。这种可追溯性在业务使用中带来了极大的安心感。
4. 实际使用场景中的差异
来看一些具体例子。设想一家企业内部存有 20 份人事相关规章:《劳动规则》《人事考核制度规章》《骚扰应对手册》《薪酬・奖金・离职金规章》等。
场景 1:「请比较《劳动规则》与《人事考核制度规章》中评估面谈的频率」
- RAG 的情况:只取到《劳动规则》的片段,回答「每年一次」。无法取到《人事考核制度规章》的片段,比较无从成立。最糟时还会擅自编造「《人事考核制度规章》中规定为半年一次」。
- skill 模式的情况:AI 从目录同时选择《劳动规则》和《人事考核制度规章》,阅读各自相关条目后,准确回答:「《劳动规则》记载为每年一次,《人事考核制度规章》记载为每季度一次。」
场景 2:「请告知育儿休假复职时的流程」
- RAG 的情况:能收集包含「育儿休假」关键词的片段,但无法整合复职后手续、对考核的影响等跨多份规章的信息,回答容易片面化。
- skill 模式的情况:阅读多份与「育儿休假」相关的规章后,按时间顺序整理回答:复职前手续 → 复职时的工作调整 → 复职后对考核的影响。
场景 3:「API 密钥的发行方法是?」(无相关文档)
- RAG 的情况:从相关性较低的文档强行抓取片段,编造看似合理的步骤。
- skill 模式的情况:在确认目录后,明确表示:「该信息未包含在已注册的文档中。」并建议向负责人咨询。
业务上能放心使用的,显然是后者。
5. 为什么「从目录顺藤摸瓜」更适合企业知识
企业内部知识与 Web 上无序堆积的信息有着不同的特性:
- 结构化:规章按章节组织,手册按步骤组织,FAQ 按分类组织
- 更新单位是文档:规章修订基本上是「整份文档替换」
- 正确性直接关乎业务:法务、人事、财务一旦误解就会引发严重问题
这些特性与「目录导航」的契合度远胜于 RAG。
Monoshiri AI 围绕这种契合度做了彻底的设计。客户将文档放入文件夹后,AI 会自动构建语义分组与目录,每当问题进来时,便从目录顺藤摸瓜阅读所需文档。客户新增或替换文档后,目录也会自动更新,因此运营成本也比 RAG 大幅降低。
6. Monoshiri AI 对客户的承诺
借此次切换至 skill 模式,Monoshiri AI 向客户承诺以下三点。
1. 不知道就明确说不知道
对知识库中没有记载的提问,不会编造看似合理的回答,而是明确返回「没有相关记录」。这是防止业务判断失误最重要的原则。
2. 一定标注出处
AI 的回答必定附带**「阅读了哪份文档的哪一部分以作答」。为便于阅读者直接核对原文档**,出处会精确到具体的文件名与对应段落。
3. 文档增多也能保持精度
企业知识必然会随时间累积。skill 模式由于通过目录筛选,即使文档达到 100、500、1000 份,回答精度依然稳定。绝不会出现「一开始还能回答,文档一多就变迟钝」的情况。
总结 —— 知识 AI 重要的不是「快」,而是「准」
随着 ChatGPT 和 Claude 等通用 AI 的普及,「凡事问 AI」的期待越来越高。但企业业务中所需的知识 AI,并非通用 AI 的流畅作答,而是根植于自家文档的精确回答。
Monoshiri AI 将「正确性」作为技术选型的最高优先级后得出的结论是:skill 模式比 RAG 更契合客户的业务需求。
如果您正因「担心 AI 胡编乱造,不敢将其应用于企业知识库」而犹豫,欢迎亲身体验一次 skill 模式的回答品质。
相关文章
想了解技术决策详情的读者:关于 skill 模式迁移的技术背景与实现细节,开发者本人在 Qiita 上发表了更深入的文章(日文):RAG をやめました -- ナレッジAI SaaS「ものしりAI」 が Corpus2Skill (skill モード) に全面移行した理由。
分享这篇文章
相关文章

「RAG 不需要」是真的吗?企业知识 AI 选型的 6 个判断维度
随着长文本上下文 LLM 的出现,「RAG 不需要」的论调越来越多。本文用 6 个判断维度梳理真正不需要的场景与依然需要 RAG 的场景,为企业知识 AI 选型提供务实指南。

什么是RAG?通俗解读彻底改变企业文档搜索的核心技术
面向非技术人员解读RAG(检索增强生成)的工作原理。梳理传统企业文档搜索的局限、RAG带来的变化,以及企业部署时需要注意的要点。

RAG已经过时了吗?长文本上下文时代的知识库设计
随着1M token级长文本上下文的普及,"RAG不再需要"的声音开始出现。本文从成本、权限、精度等五个维度,解析企业知识库当前的最优解。