
「Gemini 2.5 已支持 1M token」「Claude 的上下文窗口又扩大了」。看到这样的新闻后,最近经常有 IT 负责人来咨询:
「RAG 是不是已经不需要了? 听说全部塞进提示词就行了。」
确实,长文本上下文 LLM(一次能读取大量文本的大语言模型)进化迅速,社交媒体和博客上「RAG 不需要」「RAG 没必要」的论调也在增加。然而,如果直接照单全收并据此做决策,在生产环境运维中栽跟头的企业屡见不鲜。
本文将梳理「RAG 不需要论」出现的背景,并面向正在考虑引入企业知识 AI 的信息系统负责人和经营层,用 6 个判断维度教你判断自家场景是否真的不需要 RAG。
本文要点
- 「RAG 不需要」论调流行的背景
- 真正不需要 RAG 的场景(个人 / 小规模知识库)的成立条件
- 企业知识用途下依然需要 RAG 的 6 个判断维度
- 长文本上下文 / RAG / skill 模式 —— 应如何选型的判断流程
- Monoshiri AI 的定位,以及企业知识 AI 选型不踩坑的要点
为什么现在会说「RAG 不需要」
「RAG 不需要论」的流行确实有其技术背景。我们先来梳理一下到底发生了什么变化。
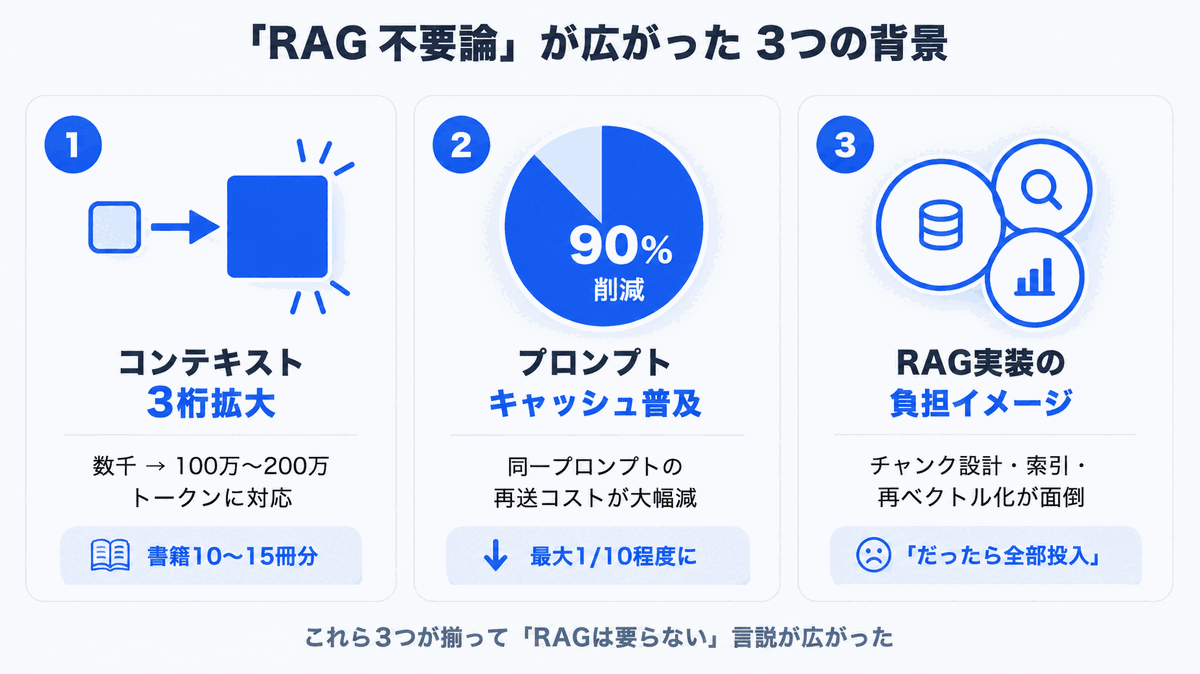
1. 上下文窗口扩大了 3 个数量级
仅仅几年前,大语言模型一次能处理的信息量还只有 几千 token(中文几千字)的级别。但在 2024~2026 年间迅速扩张,目前主流模型大多已支持 100 万(1M)~200 万(2M)token。
1M token 换算成中文文本,相当于原稿纸 3,500 张、书籍 10~15 册的体量。「一本商品手册整本贴进提示词来提问」的时代确实已经到来。
2. 提示词缓存让「全部投入」的成本降下来了
主流 LLM 提供商都提供了 提示词缓存(对相同提示词重复请求给予折扣的机制)。这使得即便每次都把固定的企业内部文档载入提示词,缓存命中时的成本也能压缩到原本的约 1/10。
3. 「RAG 实施太麻烦」的印象深入人心
RAG 概念虽然简单,但要在生产环境稳定运行,需要以下知识与积累:
- 文档分块切分的设计
- 向量数据库选型与索引设计
- 检索精度调优(重排序、混合检索等)
- 文档更新时的重新向量化流水线
许多企业在尝试自建 RAG 时受挫。「想跳过麻烦的 RAG,用长文本上下文简单搞定」 的心理因此自然产生。
结论:真正不需要 RAG 的场景需满足「3 个条件」
先说结论。「RAG 不需要」成立的场景,仅限于 同时满足以下 3 个条件 的情形:
- 目标文档总量在 1M token 以内(书籍 10~15 册以内)
- 所有用户都可以查看相同的文档集(不需要权限分离)
- 文档更新频率低,或更新时能接受重新生成全部提示词的成本
满足这 3 条件的典型例子是:个人开发者使用的技术书 Q&A、针对特定项目数十个文件的分析、对一本商品手册的问答等。
反过来说,企业内部知识用途的绝大多数情况,都会被这 3 条件中的某一条卡住。从这里开始,我们将分 6 个判断维度,看看为什么在企业用途下 RAG 依然是必需的。
判断自家是否需要 RAG 的 6 个维度
这是一份用于不被「RAG 不需要论」蒙住眼睛、对照自家场景检查的清单。只要有一项命中,单靠长文本上下文运维就是危险信号。
维度 1:文档量 —— 全公司文档总量真的能装进 1M 吗
首先,把自家所有内部文档加起来大概有多少 token,粗略估算一下即可。
| 文档种类 | 目安 token 数 |
|---|---|
| 劳动规则、人事规章 | 5 万~20 万 |
| 业务手册(按部门) | 10 万~50 万 |
| 产品文档 | 数十万~数百万 |
| 会议记录、企业内部 Wiki | 数百万~数千万 |
| 客户应对历史、支持工单 | 数千万~亿级 |
中型企业一家的内部文档总量,如果把会议记录和 Slack 日志也算进来,通常会达到数千万~数亿 token 的规模。1M、2M 远远不足以「全部喂给模型」。
「那只把相关文档放进提示词就好了」—— 但 这本身就是 RAG 的思路。你必须要有某种「筛选出相关文档的机制」。
维度 2:权限分离 —— 是不是所有人都能看相同的文档
企业知识中,按用户、按部门设置不同访问权限是常态:
- 只有人事部门才能查看的薪资 / 绩效资料
- 只有财务部门才能查看的财务信息
- 仅项目成员可见的机密资料
- 仅高管可见的经营资料
在长文本上下文运维下,需要为每个用户组装不同的文档集放入提示词。这会带来 3 个问题:
- 缓存效率下降:每个用户的提示词不同,缓存命中率随之降低
- 权限逻辑复杂化:「这条信息能不能放进去」的判断渗透到提示词生成层
- 信息泄漏风险:权限判定出错就直接导致机密信息外泄
在检索阶段就能按用户权限过滤的 RAG 型方案,在设计上要自然得多。这与其说是技术选型问题,不如说是企业信息系统的基本原则问题。
维度 3:更新频率 —— 文档变化有多频繁
企业内部文档不是静态的。规章修订、新品发布、议事录追加、FAQ 更新 —— 几乎每天都在变化。
| 方案 | 新增 1 份文档时的处理 |
|---|---|
| RAG | 仅向量化新增部分并注册到索引(数秒级) |
| 长文本上下文全量投入 | 整体重新生成提示词,缓存也要重建 |
差分更新的能力强不强直接关系到运维成本。在文档以日 / 小时为单位更新的环境中,RAG 的优势毋庸置疑。
维度 4:查询频率 —— 每天会有多少次提问
企业知识 AI 一旦推广开来,查询量会逐步上升。最初每天数十次,定着后就会增长到每天数百~数千次。
这时起作用的是 每次查询的输入 token 数。假设把 1M(=100 万)token 的内部文档放进提示词:
- 每次查询:数十元~数百元(因模型而异)
- 每天 1,000 次查询:每月数十万~数百万元
- 即便用提示词缓存折扣,首次调用与更新后的重新缓存仍按全价计费
而 RAG 只发送相关分块,每次查询只需数千~数万 token。成本差异是字面意义上的数量级差距。
维度 5:精准提问的精度 —— 能否容忍 "Lost in the Middle"
长文本上下文容易让人误以为「AI 会认真读完」,但 多项研究指出,LLM 会更关注提示词的开头与末尾,而容易漏掉中间部分的信息。这就是 "Lost in the Middle" 现象。
- 在「X 的申请截止日期是几号?」这类精准事实抽取上,精度下降尤为明显
- 提示词越长,劣化越严重
- 即使是宣称支持 1M 的模型,也有观点认为实际能保持高精度的大约只有数十万 token
「抽取某一具体语句」的任务,反而是只发送相关数页的 RAG 更稳定,这是当下的实情。
维度 6:审计与说明责任 —— 能否说明「为什么这样回答」
业务中使用 AI 时,特别是法务、人事、财务这类以正确性为业务前提的部门,「AI 是基于哪份文档的哪一部分作答的」 必须可以事后追溯。
- 长文本上下文全量投入:只能说「全都读了」,根据所在位置模糊
- RAG:可以明示检索命中的分块出处
- skill 模式(后述):从目录顺藤摸瓜的路径直接作为历史记录保留
审计与说明责任要求越高的业务,依据的可追溯性越是技术选型的最重要维度。

你的组织该选择哪一种 —— 判断流程
基于以上维度,下面整理出一个判断流程,帮你为自家场景选出合适的方案。
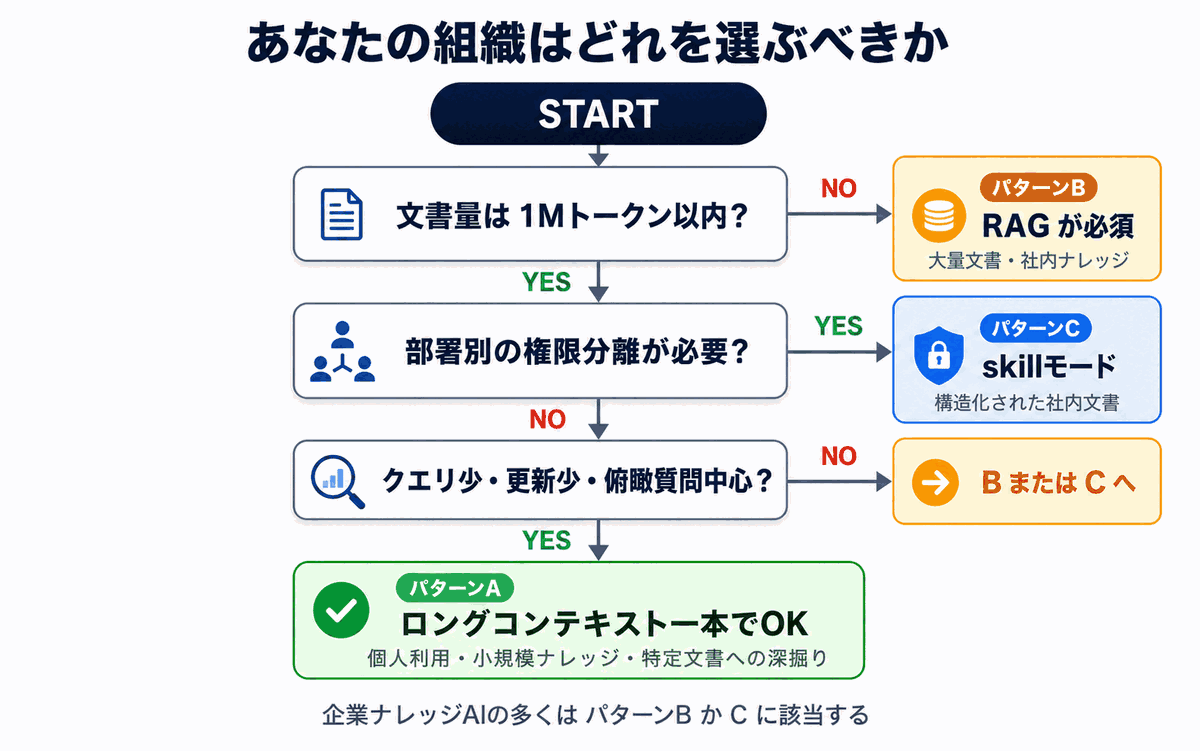
模式 A:单靠长文本上下文即可的情形
如果以下条件全部成立,那么不用 RAG、仅用长文本上下文运维就足够了:
- 目标文档在 1M token 以内(例:商品手册一本、合同数份、特定项目的议事录)
- 所有用户都可以查看相同的文档
- 文档更新频率每月数次以下
- 查询数每天数十次以下
- 「整体俯瞰式分析」类提问为主
典型场景:个人使用、小规模知识库分析、对特定文档的深挖问答
模式 B:RAG 几乎是必需的情形
只要以下任何一条命中,RAG(或同等的检索型方案)几乎就是必需的:
- 文档量超过数千件、数百万 token
- 需要按部门 / 项目分离权限
- 文档以日次以上的频率被新增 / 更新
- 全员日常提问(查询数大)
- 「某规章第几条」这类精准提问为主
典型场景:企业内部知识库、客户支持 FAQ、产品文档检索
模式 C:为企业内部知识量身打造的「第三条路」
实际上,企业内部知识用途下,仅靠「RAG vs 长文本上下文」的二元对立往往得不出答案:
- RAG 擅长大量文档,但幻觉风险残存
- 长文本上下文在成本与权限分离上行不通
- 想要兼得二者之长
因此,最近开始受到关注的方向是 直接利用文档原本就具备的章·节·项等层级结构的方式。Monoshiri AI 采用的 skill 模式(Corpus2Skill) 就是其代表——把「目录」交给 AI,让它自己去查阅必需的文档。
详细的技术判断与迁移经过请参阅 我们放弃了 RAG —— Monoshiri AI 全面迁移到 Corpus2Skill 的原因。
常见误解与正确的理解
主张「RAG 不需要」的论调中,常常包含一些误解。下面整理几条具有代表性的:
误解 1:「上下文一旦变大,就不需要检索了」
正确的理解:上下文无论扩大到多大,企业全公司的文档总量都会以更快的速度持续增长。况且权限分离、成本、Lost in the Middle 等问题,都不会因为上下文扩大而消失。
误解 2:「RAG 幻觉太多,不堪用」
正确的理解:幻觉是 RAG 设计与运维的问题,只要在合适的检索精度、出处明示、以及「无记录」时如实告知的设计上下功夫,就能加以抑制。比起一刀切地否定,正确做法是在认清 RAG 结构性弱点的前提下,选择补足它的方案(混合型、skill 模式等)。
误解 3:「长文本上下文就不会出现幻觉」
正确的理解:由于 Lost in the Middle 现象,长文本中央部分的信息漏读依然会发生。「全部装进去就完美」是不成立的。
误解 4:「RAG 已经是稳定不再进化的旧技术」
正确的理解:RAG 周边目前仍在快速进化。Agentic RAG、Cache-Augmented Generation、Corpus2Skill 等新一代衍生形态层出不穷。与其说「RAG 不需要」,不如说「RAG 的形态正在进化」。
Monoshiri AI 的定位 —— 超越「RAG vs 不需要」
Monoshiri AI 自身在服务初期也对 RAG、长文本上下文、混合方案进行了全面验证,最终走到了 充分发挥企业内部知识固有结构(规章·手册·FAQ 的章节与层级)的 skill 模式(Corpus2Skill)。
skill 模式在以下几个方面,针对企业知识用途做了优化:
- 正确性:从目录顺藤摸瓜,因检索失误而产生的幻觉很难发生
- 成本:只阅读必要文档,避免长文本上下文全量投入的成本爆炸
- 权限:与文件夹级访问控制天然契合
- 更新:新增文档后目录也会自动更新
- 审计:「读了哪份文档的哪部分」会作为历史记录保留下来
也就是说,Monoshiri AI 的立场并不是「RAG 不需要」,而是 「采用了一种超越 RAG、也超越长文本上下文、专为企业知识用途优化的方式」。
Monoshiri AI 的主要功能见 功能介绍,价格方案见 价格方案。与其他 AI 知识 SaaS 的差异请参阅 比较页面。
判断「RAG 不需要」之前应做的 3 个步骤
最后,整理一下在自家实际判断「需不需要 RAG」时的实务步骤。
步骤 1:估算文档量
把企业内部文档的总 token 数粗略算出来即可。总字符数 ÷ 1.5 就能得到 token 数的近似值。能否控制在 1M token 以内,是第一道分水岭。
步骤 2:梳理权限要求
按部门、职级、项目,把谁可以访问哪些文档整理成表格。只要有一个分离需求存在,仅靠长文本上下文就是危险的。
步骤 3:试算预期查询数与成本
把引入后的预期使用人数 × 每天每人查询次数估算出来,分别计算长文本上下文 / RAG / skill 模式的月度成本。规模越大,差距越夸张。
总结
本文用 6 个判断维度对「RAG 不需要论」进行了检验。要点整理如下:
- 「RAG 不需要」成立的场景,仅限于同时满足文档量·权限·更新频率 3 条件的个人 / 小规模知识库
- 企业知识用途的绝大多数情况,都会在文档量·权限·更新·查询频率·精准精度·审计这 6 个维度中的某个上要求 RAG 类机制
- 「RAG vs 长文本上下文」并非二元对立,按用途分工或加以融合才是现实解
- 如果是企业内部知识专用,那么超越二者的 skill 模式(Corpus2Skill)这第三条路也值得考虑
- 判断不应基于感觉,而应基于文档量·权限·查询数·成本的试算结果
「RAG 不需要」是一种朗朗上口的论调,但它只是 AI 趋势中的某个切面。是否适合自家场景,只能依据自家文档量与需求来判断。希望本文的 6 个判断维度,能成为这一判断的起点。
相关文章
分享这篇文章
相关文章

什么是 Corpus2Skill?RAG 与 skill 模式的区别详解
「担心 AI 胡编乱造」「复杂问题无法回答」。本文以实际案例解析 RAG 的幻觉问题与检索精度局限,以及 Monoshiri AI 如何通过 skill 模式加以解决。

什么是RAG?通俗解读彻底改变企业文档搜索的核心技术
面向非技术人员解读RAG(检索增强生成)的工作原理。梳理传统企业文档搜索的局限、RAG带来的变化,以及企业部署时需要注意的要点。

RAG已经过时了吗?长文本上下文时代的知识库设计
随着1M token级长文本上下文的普及,"RAG不再需要"的声音开始出现。本文从成本、权限、精度等五个维度,解析企业知识库当前的最优解。