
「Gemini 2.5 が1Mトークンに対応した」「Claude のコンテキストウィンドウが拡大した」。こうしたニュースを目にしたIT担当者の方から、最近よくこんな相談を受けます。
「RAGってもう要らないんじゃないですか? 全部プロンプトに突っ込めば済むって聞いたんですが」
たしかに、ロングコンテキストLLM(長文を一度に読み込める大規模言語モデル)の進化は目覚ましく、SNSやブログでも「RAG 不要」「RAG いらない」という言説が増えています。しかし、この主張をそのまま受け取って意思決定すると、本番運用でつまずく企業が後を絶ちません。
本記事では、「RAG不要論」が出てくる背景を整理したうえで、自社のユースケースで本当にRAGが不要かどうかを6つの判断軸で見極める方法を、社内ナレッジAIを検討中の情報システム担当者・経営層向けに解説します。
この記事で分かること
- 「RAG 不要」という言説が広がっている背景
- 本当にRAGが不要なケース(個人・小規模ナレッジ)の条件
- 企業ナレッジ用途で依然RAGが必要となる6つの判断軸
- ロングコンテキスト・RAG・skillモード -- どれを選ぶべきかの判断フロー
- ものしりAIの立ち位置と、企業ナレッジAI選びで失敗しないコツ
なぜ今「RAG 不要」と言われるのか
「RAG 不要論」が広がっているのには、確かに技術的な理由があります。まずは何が変わったのかを整理しましょう。
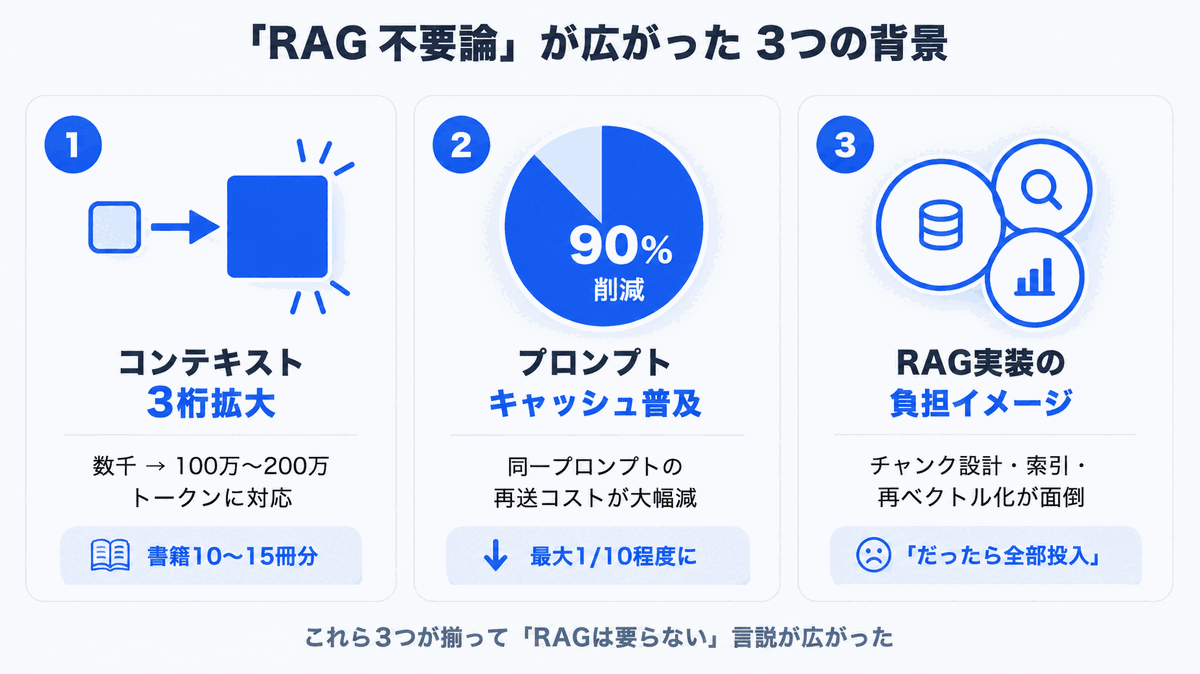
1. コンテキストウィンドウが3桁拡大した
ほんの数年前まで、大規模言語モデルが一度に扱える情報量は 数千トークン(日本語で数千字)程度でした。それが2024〜2026年にかけて急速に拡大し、現在では主要モデルの多くが 100万(1M)〜200万(2M)トークン に対応しています。
1Mトークンは日本語換算で原稿用紙3,500枚、書籍10〜15冊分に相当します。「商品マニュアル1冊くらいなら、まるごとプロンプトに貼って質問できる」時代になったのは確かです。
2. プロンプトキャッシュで「全部投入」のコストが下がった
主要なLLMプロバイダーは プロンプトキャッシュ(同じプロンプトを再送した際に料金を割引する仕組み)を提供しています。これにより、固定の社内文書を毎回プロンプトに載せる運用でも、キャッシュヒット時のコストは本来の1/10程度にまで圧縮できるようになりました。
3. 「RAGの実装は大変」というイメージが定着した
RAGは概念こそシンプルですが、本番運用には以下のようなノウハウが必要です。
- ドキュメントのチャンク分割設計
- ベクトルDBの選定とインデックス設計
- 検索精度のチューニング(再ランキング、ハイブリッド検索など)
- 文書更新時の再ベクトル化パイプライン
これを内製しようとして挫折した経験を持つ企業は少なくありません。「面倒なRAGをスキップして、ロングコンテキストでシンプルに済ませたい」 という心理が働くのは自然なことです。
結論: 本当にRAGが不要なケースは「3つの条件」を満たす場合
最初に結論を述べます。「RAG 不要」が成り立つのは、以下の 3つの条件をすべて満たす ケースに限られます。
- 対象文書が1Mトークン以内に収まる(書籍10〜15冊以内)
- 全ユーザーが同じ文書セットを参照してよい(権限分離が不要)
- 文書の更新頻度が低い、または更新時に全プロンプト再生成のコストを許容できる
この3条件に当てはまる典型例は、個人開発者が使う技術書のQ&A、特定プロジェクトの数十ファイルを対象とした分析、商品マニュアル1冊への質問応答などです。
逆に言えば、企業の社内ナレッジ用途のほとんどは、この3条件のどれかに引っかかります。ここから先は、なぜ企業用途でRAGが依然として必要なのかを、6つの判断軸に分けて見ていきます。
自社にRAGが必要かを判断する6つの軸
「RAG 不要論」を鵜呑みにせず、自社のユースケースに照らし合わせるためのチェックリストです。1つでも該当すれば、ロングコンテキスト一本での運用は危険信号と考えてください。
軸1: 文書量 -- 全社の文書はそもそも1Mに入るのか
まず、自社の社内文書を全部足したら何トークンになるかを粗くてよいので見積もってみてください。
| 文書の種類 | 目安トークン数 |
|---|---|
| 就業規則・人事規程 | 5万〜20万 |
| 業務マニュアル(部署単位) | 10万〜50万 |
| 製品ドキュメント | 数十万〜数百万 |
| 議事録・社内Wiki | 数百万〜数千万 |
| 顧客対応履歴・サポートチケット | 数千万〜億単位 |
中堅企業1社の社内文書総量は、議事録やSlackログを含めれば 数千万〜数億トークン に達することが普通です。1Mや2Mでは「全部食わせる」には到底足りません。
「では関連する文書だけプロンプトに載せればいい」となりますが、それは結局RAGの考え方そのものです。何らかの形で「関連文書を選び出す仕組み」が必要になります。その中核を担うのが、文章の意味の近さで該当文書を探すセマンティック検索(意味検索)です。仕組みと導入手順は別記事で図解しています。
軸2: 権限分離 -- 全員が同じ文書を見てよいのか
企業ナレッジには、ユーザーや部署ごとにアクセス権が異なるのが普通です。
- 人事部しか見られない給与・評価資料
- 経理部しか見られない財務情報
- プロジェクトメンバー限定の機密資料
- 役員限定の経営資料
ロングコンテキスト運用では、ユーザーごとに異なる文書セットをプロンプトに組み立てる 必要があります。これには3つの問題があります。
- キャッシュ効率の低下: ユーザーごとにプロンプトが変わると、プロンプトキャッシュのヒット率が下がる
- 権限ロジックの複雑化: 「この情報を載せていいか」の判断がプロンプト生成層に入り込む
- 情報漏洩リスク: 権限判定のミスがそのまま機密情報の流出につながる
検索段階でユーザー権限に応じてフィルタできるRAG型のほうが、設計上はるかに素直 です。これは技術選定というより、企業情報システムの基本原則の問題です。
軸3: 更新頻度 -- 文書はどれくらいの頻度で変わるか
社内文書は静的ではありません。規程改定、新製品発表、議事録追加、FAQの更新 -- 毎日のように何かが変わります。
| アプローチ | 文書1件追加時の動き |
|---|---|
| RAG | 追加分だけをベクトル化してインデックスに登録(数秒) |
| ロングコンテキスト全投入 | プロンプト全体を作り直し、キャッシュも再構築 |
差分更新に強いか弱いかは運用コストに直結します。日次・時間次で文書が更新される環境では、RAGの優位性は揺らぎません。
軸4: クエリ頻度 -- 1日あたり何件の質問が来るか
社内ナレッジAIは、導入が進むほどクエリ数が増えます。最初は数十件/日でも、定着すれば数百〜数千件/日に伸びます。
ここで効いてくるのが 1クエリあたりの入力トークン数 です。仮に社内文書を1M(=100万)トークン分プロンプトに載せると、
- 1クエリあたり: 数十円〜数百円(モデルにより異なる)
- 1日1,000クエリの場合: 月間数十万円〜数百万円
- プロンプトキャッシュで割り引いても、ファースト呼び出しや更新後の再キャッシュにフルコストがかかる
RAGなら関連チャンクのみ送るため、1クエリあたり数千〜数万トークンで済みます。コスト差は文字通り桁違いです。
軸5: ピンポイント質問の精度 -- "Lost in the Middle"を許容できるか
ロングコンテキストで「全部読んでくれる」と思いがちですが、LLMはプロンプトの先頭と末尾に強く注目し、中央部分の情報を取りこぼしやすい ことが複数の研究で指摘されています。これは "Lost in the Middle" と呼ばれる現象です。
- 「Xの申請締切は何日?」のようなピンポイント事実抽出で精度低下が顕著
- プロンプトが長くなるほど劣化が加速する
- 1M対応モデルでも、実質的に高精度を保てるのは数十万トークン程度という指摘がある
「特定の一文を引く」タスクは、関連する数ページだけを送るRAGのほうが安定するのが実情です。
軸6: 監査と説明責任 -- 「なぜそう答えたか」を示せるか
業務でAIを使うとき、特に法務・人事・経理のような正確さが業務の前提となる部署では、「AIがどの文書のどこを根拠に答えたか」 を後から追跡できることが重要です。
- ロングコンテキスト全投入: 「全部読みました」としか言えず、根拠箇所の特定が曖昧
- RAG: 検索でヒットしたチャンクの出典を明示できる
- skillモード(後述): 目次から辿った経路がそのまま履歴として残る
監査・説明責任が問われる業務ほど、根拠の追跡可能性が技術選定の最重要軸 になります。

あなたの組織はどれを選ぶべきか -- 判断フロー
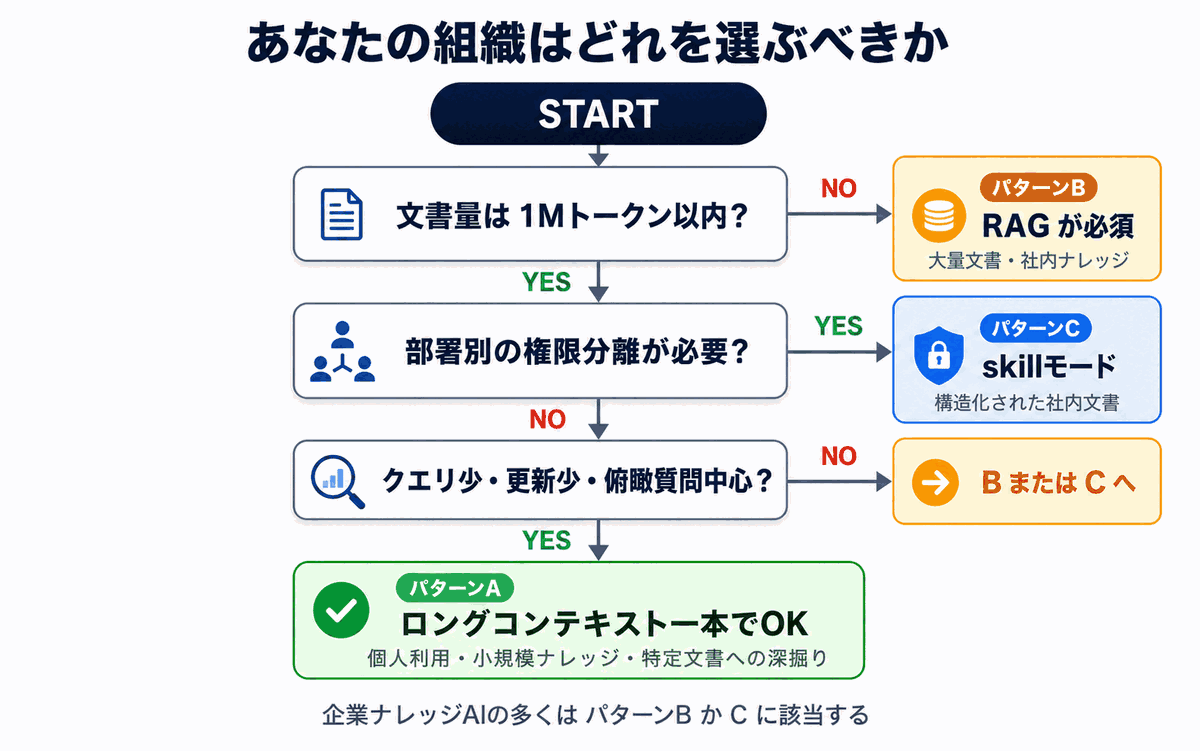
ここまでの軸を踏まえて、自社のユースケースに合うアプローチを選ぶ判断フローを整理します。
パターンA: ロングコンテキスト一本でよいケース
以下のすべてに当てはまる場合、RAGなしのロングコンテキスト運用で十分です。
- 対象文書が1Mトークン以内(例: 商品マニュアル1冊、契約書数通、特定プロジェクトの議事録)
- 全ユーザーが同じ文書を参照してよい
- 文書の更新頻度が月数回以下
- クエリ数が1日数十件以下
- 「全体を俯瞰した分析」が中心の質問
典型例: 個人利用、小規模ナレッジの分析、特定文書への深掘り質問
パターンB: RAGが必須なケース
以下のいずれかに該当する場合、RAG(または同等の検索的アプローチ)はほぼ必須です。
- 文書量が数千件・数百万トークンを超える
- 部署別・プロジェクト別の権限分離が必要
- 文書が日次以上の頻度で追加・更新される
- 全社員が日常的に質問する(クエリ数が多い)
- 「特定の規程の何条」のようなピンポイント質問が中心
典型例: 企業の社内ナレッジベース、カスタマーサポートのFAQ、製品ドキュメント検索
パターンC: 社内ナレッジに最適化された第三の道
実は、企業の社内ナレッジ用途では「RAG vs ロングコンテキスト」の二項対立だけでは答えが出ないことが多いのが実情です。
- RAGは大量文書には強いが、ハルシネーションのリスクが残る
- ロングコンテキストはコストと権限分離で詰む
- 両方のいいとこ取りが欲しい
そこで最近注目されているのが、ドキュメント本来の章・節・項といった階層構造を活かす方式です。ものしりAIが採用している skillモード(Corpus2Skill) がその代表例で、AIに「目次」を渡して必要な文書だけを自分で読みに行かせる仕組みです。
詳しい技術判断と移行の経緯はRAGをやめました -- ものしりAIがCorpus2Skillに全面移行した理由で公開しています。
よくある誤解と正しい捉え方
「RAG 不要」を主張する論調には、しばしば誤解が含まれています。代表的なものを整理します。
誤解1: 「コンテキストが大きくなれば検索は要らなくなる」
正しくは: コンテキストがどれだけ大きくなっても、企業全体の文書量はそれを上回るペースで増え続けます。さらに権限分離・コスト・Lost in the Middleの問題は、コンテキスト拡大では解消しません。
誤解2: 「RAGはハルシネーションが多いから使い物にならない」
正しくは: ハルシネーションはRAGの設計と運用の問題であり、適切な検索精度・出典明示・「該当なし」を返す設計を入れれば抑制できます。RAGの構造的な弱点を踏まえつつ、補完するアプローチ(ハイブリッド型、skillモード等)を選ぶのが筋です。
誤解3: 「ロングコンテキストならハルシネーションが起きない」
正しくは: Lost in the Middle 現象により、長文の中央部分の情報を取りこぼすケースは依然として発生します。「全部入れたから完璧」ではありません。
誤解4: 「RAGはもう枯れた技術なので進歩しない」
正しくは: RAG周辺は今も急速に進化しており、Agentic RAG、Cache-Augmented Generation、Corpus2Skill のような新世代の派生形が次々と登場しています。「RAG不要」ではなく「RAGの形が進化している」と捉えるべきです。
ものしりAIの立ち位置 -- 「RAG vs 不要」を超えて
ものしりAI自身も、サービス開始時にRAG・ロングコンテキスト・ハイブリッドのすべてを検証しました。その結果、社内ナレッジ特有の構造(規程・マニュアル・FAQの章立て・階層)を最大限活かすskillモード(Corpus2Skill) にたどり着きました。
skillモードは以下の点で、企業ナレッジ用途に最適化されています。
- 正確さ: 目次から辿るため、検索ミスによるハルシネーションが起きにくい
- コスト: 必要な文書だけを読むため、ロングコンテキスト全投入の費用爆発を回避
- 権限: フォルダ単位のアクセス制御と整合性が取れる
- 更新: 新しい文書を追加すれば目次も自動更新
- 監査: 「どの文書のどこを読んだか」が履歴として残る
つまり、ものしりAIにおいては 「RAG が不要」ではなく「RAGも長文コンテキストも超える、社内ナレッジ用途に特化した方式」 を採用しているのです。
ものしりAIの主要機能は機能一覧、料金体系は料金プランで公開しています。他のAIナレッジSaaSとの違いは比較ページもご覧ください。
「RAG 不要」を判断する前にやるべき3ステップ
最後に、自社で実際に「RAG 不要 or 必要」を判断する際の実務ステップをまとめます。
ステップ1: 文書量を見積もる
社内文書の総トークン数を粗くてよいので算出してください。総文字数 ÷ 1.5 でおおよそのトークン数になります。1Mトークンに収まるかどうかが第一の分かれ目です。
ステップ2: 権限要件を整理する
部署別・役職別・プロジェクト別に、誰がどの文書にアクセスしてよいかを表で整理してください。1つでも分離が必要なら、ロングコンテキスト一本は危険です。
ステップ3: 想定クエリ数とコストを試算する
導入後の想定利用ユーザー数 × 1日あたりのクエリ回数を見積もり、ロングコンテキスト・RAG・skillモードのそれぞれで月額コストを比較してください。スケールするほど差が広がります。
まとめ
本記事では、「RAG 不要論」を6つの判断軸で検証しました。要点を整理します。
- 「RAG 不要」が成り立つのは、文書量・権限・更新頻度の3条件をすべて満たす個人・小規模ナレッジに限られる
- 企業ナレッジ用途のほとんどは、文書量・権限・更新・クエリ頻度・ピンポイント精度・監査の6軸のいずれかでRAG的な仕組みが必要になる
- 「RAG vs ロングコンテキスト」は二項対立ではなく、用途に応じて使い分け、または統合するのが現実解
- 社内ナレッジに特化するなら、両者を超える skillモード(Corpus2Skill)のような第三の道もある
- 判断は感覚ではなく、文書量・権限・クエリ数・コストの試算で行うのが鉄則
「RAG 不要」というキャッチーな言説は、AIトレンドの一面を切り取ったものです。自社のユースケースに合うかどうかは、自社の文書量と要件で判断するしかありません。本記事の6つの軸が、その判断の起点になれば幸いです。
関連記事
この記事をシェア
関連記事
2026年のAIエージェント最新動向と、社内ナレッジ活用への落とし込み方
2026年のAIエージェント・最新LLM・エンタープライズRAGの動向を整理し、情シス・DX担当者が社内ナレッジ活用に落とし込むための実務ポイントを解説。精度・権限・運用の観点でものしりAIをどう位置づけるかも示します。

RAGの限界とは?ハルシネーションを防ぐskillモードを実例で解説【2026年版】
RAGはなぜ「嘘の回答(ハルシネーション)」を起こすのか。複数文書の比較・大量ドキュメント・該当なし質問でつまずくRAGの構造的な限界と、ものしりAIがskillモード(Corpus2Skill)でどう解決したかを、人事規程の実例とともに解説します。

RAGとは何か?社内文書検索を劇的に変える仕組みをわかりやすく解説
RAG(検索拡張生成)の仕組みを非エンジニア向けに解説。従来の社内文書検索の限界と、RAGがもたらす変化、企業導入時の注意点までをまとめて紹介します。
ものしりAIを無料で試してみませんか?
ドキュメントをアップロードするだけで、AIに質問できる環境が作れます。ユーザー数無制限の無料プランで、まずはお試しください。
無料で始めるクレジットカード不要 / 最短1分で利用開始