
「无论在检索框里输入什么,想要的文件都出不来」。明明引入了全文检索,最后还是口头去问资深员工。共享文件夹里分明有文档,却始终从检索里找不到。这种状态,并不是因为你的检索技巧不够,而是因为关键词检索这套机制本身存在结构性的极限。
本文并非「解决方案介绍」,而是一份用于诊断检索失败具体现象的目录手册。我们把企业文档盘活不起来的原因归纳为 7 种模式。请对照自家的情况判断属于哪一种,从而看清究竟该改变什么。解决的方向会在文章后半部分简洁梳理,详细的机制则引导至相关文章。
本文要点
- 关键词检索无法盘活企业文档的 7 种失败模式
- 即便引入全文检索 AI 工具,极限依然残留的原因
- PDF、扫描件、表述不一致等「按现象」区分原因的方法
- 突破极限的下一步(基于生成式 AI 的企业文档检索)
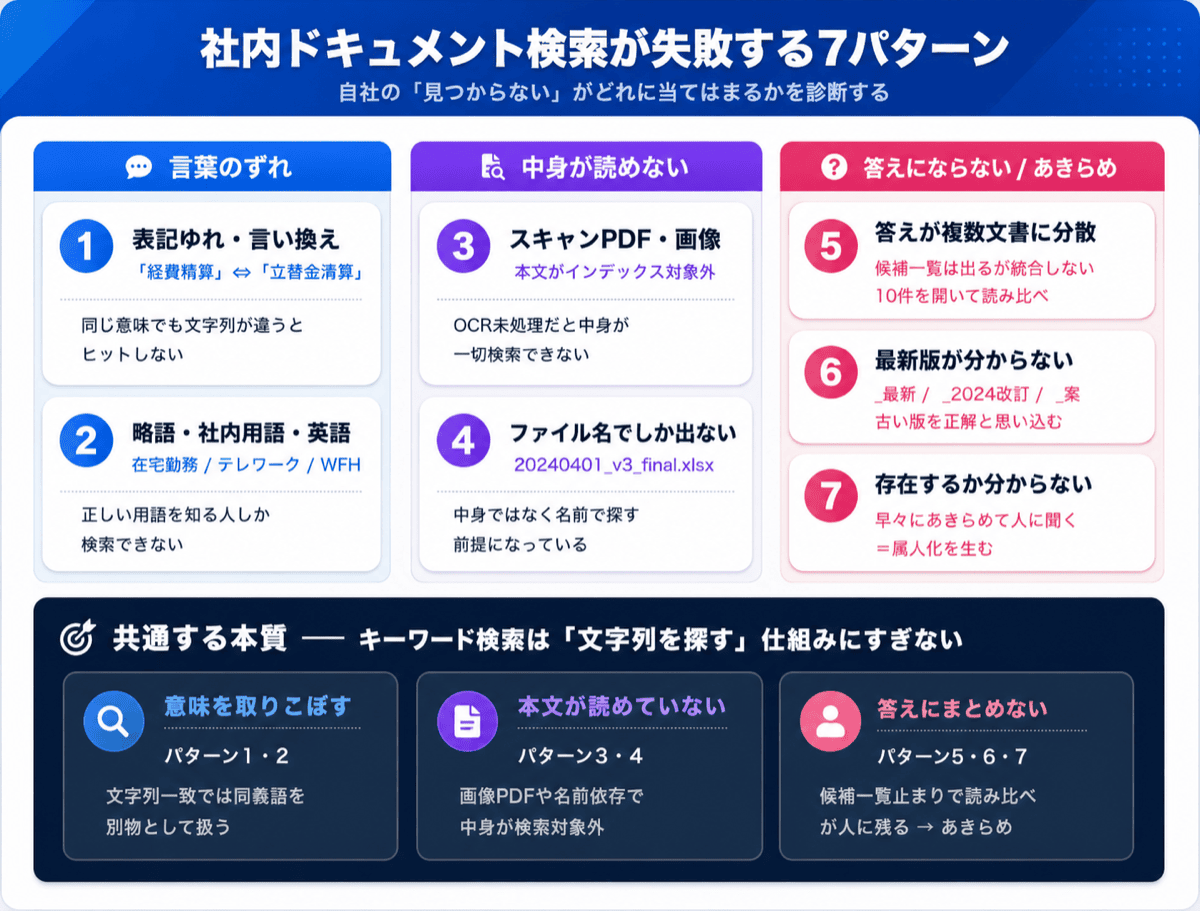
关键词检索在企业文档上失败的 7 种模式
当企业文档检索不顺利时,原因大体都落在以下 7 种之一。请一边回想自家「找不到」的经历,一边对照阅读。
模式 1:用词不同就检索不到(表述不一致、同义改写)
用「报销」检索,文档里写的却是「垫付款结算」「结算手续」。明明指的是同一件事,仅仅因为字符串不同就检索不到。企业内部混杂着各部门的「方言」,以及随年度变化而改动的称呼。人能判断为同义的词,关键词检索却当成两回事,这就是第一个极限。
模式 2:缩写、内部术语、英文表述不一致
「远程办公」「居家办公」「在家工作」「WFH」。同一种工作方式有 4 种说法,检索者输入哪一个,结果就会不同。产品代号、内部项目名的正式名称与简称的不一致同样如此。于是产生了一个前提门槛:只有知道正确术语的人才检索得到。
模式 3:PDF、扫描件的内容根本没被纳入检索对象
只是把纸张扫描而成的 PDF,作为图片贴入的表格与图示。这些东西看上去写着文字,但作为数据其实是「图片」。如果没有经过 OCR(文字识别)处理,全文检索的索引里就完全不包含正文。这是「明明应该有的文件却检索不出来」的最大原因之一。
模式 4:只能靠文件名才检索得到
许多共享文件夹检索,实质上依赖的是文件名匹配。即便正文里写着答案,只要文件名是「20240401_v3_final.xlsx」这种毫无意义的字符串,就与检索词对不上。前提是「按名字而非按内容去找」,因此一旦命名规则崩坏,检索就立刻失效。
模式 5:答案分散在多份文档里
「出差交通费最多能申请多少?」的答案,被分散在出差规章、报销手册、财务部通知这 3 个地方。关键词检索只会把疑似相关的文件罗列成一览,并不会跨多份文档把答案汇总出来。结果就是把命中的 10 个文件一个个打开、逐一比对的工作量。
模式 6:从检索结果看不出哪个是最新版
当「就业规则_最新」「就业规则_2024修订」「就业规则_草案」同时命中时,仅凭检索结果根本判断不出哪个是现行版。把旧版误当成正确答案来参考的风险,作为检索精度之前的问题,每天都在发生。
模式 7:根本不知道文档是否存在
检索后什么都没出来时,无法区分究竟是「文档不存在」还是「存在但检索不到」。这种不确定性会催生一种行为:人很快就放弃检索,转而去问「熟悉的人」。检索的失败,体现的不是检索次数,而是「放弃检索的次数」。
即便引入全文检索 AI 工具,极限依然残留的原因
「关键词检索不行,那引入全文检索引擎或检索专用的 AI 工具不就好了」。抱着这种想法引入,体感却毫无变化的案例并不少见。即便引入全文检索 AI,上述极限中的一部分依然会持续残留。
原因在于,许多全文检索工具的改进只停留在**「更快、更广地查找字符串」的方向**。索引的构建方式、检索速度即便有所提升,检索的根基仍然是「查找与输入词相近的字符串」这套机制,这一点并未改变。
- 模式 1、2 的表述不一致、同义改写,只要不靠人工维护词典(同义词库)就无法解决。持续维护内部术语词典,现实成本极高。
- 模式 3 的扫描 PDF,只要不另行 OCR 转成文本,任何检索工具都读不到内容。
- 模式 5 的多文档整合与模式 6 的最新版判断,已超出查找字符串技术的范围。这些问题不踏入「读了之后给出答案」的工序,就无法解决——而不是「查找」就能搞定。
也就是说,全文检索 AI 对「快、广地查找」这一课题有效,但企业文档盘活的真正极限,残留在「找到之后由人来读、来比对、来判断」的工序上。
判断自家失败模式的自查
属于哪种模式,决定了该出什么手。以下是简单的区分参考。
| 常见症状 | 容易对应的模式 | 本质原因 |
|---|---|---|
| 换个说法就突然命中 | 模式 1、2 | 字符串匹配导致语义遗漏 |
| 文件看得见但内容出不来 | 模式 3 | 正文未被索引(图片 PDF 等) |
| 不知道文件名就找不到 | 模式 4 | 依赖命名规则与属人化的文件夹知识 |
| 命中一大堆需要逐一比对 | 模式 5、6 | 检索返回的是「候选一览」而非「答案」 |
| 不检索直接去问人 | 模式 7 | 因不确定性而放弃、属人化 |
如果「换个说法就命中」居多,课题在于语义理解。如果「需要逐一比对」「直接去问人」居多,课题在于找到之后汇总成答案的工序。这两者都是字符串检索的延长线触及不到的领域。
突破极限的下一步 -- 从「查找」到「提问并获得答案」
这些极限中的大多数,都可以通过把检索的思路从「查找字符串」切换为「理解语义并返回答案」而走向消解。这就是所谓基于生成式 AI 的企业文档检索方式。可用 AI 查询企业内部知识的 Monoshiri AI正是以这种思路,把「查找」替换为「提问并获得答案」。
仅梳理要点:
- 按语义查找:即便像「年度带薪休假」与「带薪假」这样表述不同,只要语义相近就能当作同一信息处理(应对模式 1、2)。
- 汇总答案返回:整合分散在多份文档里的信息,返回的是要点而非候选一览(应对模式 5)。
- 只需提问即可使用:即便不知道正确的关键词或保存位置,用自然的话把想知道的事问出来即可(应对模式 4、7)。
关于这套机制的内部细节,本文不作深入。「从关键词检索到提问」这一思路转变本身,详见从「检索」到「提问」 -- AI 时代企业信息访问的新常识;按语义查找的技术与导入步骤,详见用 AI 检索企业文档的方法。
此外,表述不一致的应对、多文档整合、按文件夹整理等实际功能,汇总在功能介绍页面;各行业、各部门的用法则汇总在应用案例页面。欢迎作为判断「我们这种检索失败有没有可能解决」的参考材料来查阅。
总结
关键词检索无法盘活企业文档,并非检索者的技巧不足,而是机制的结构性极限。本文将这一极限诊断为 7 种失败模式。
- 用词偏差(模式 1、2):表述不一致、缩写、同义改写,导致同义却检索不到
- 内容读不到(模式 3、4):扫描 PDF 或依赖文件名,导致正文没被纳入检索对象
- 无法成为答案(模式 5、6):即便出了候选一览,也不会替你做多文档整合与最新版判断
- 放弃(模式 7):存在与否的不确定性,催生了放弃检索、转而问人的属人化
- 全文检索 AI 的极限:「快、广地查找」能改善,但「找到之后读了再给出答案」的工序依然残留
只要能确定自家的「找不到」属于哪种模式,就能看清究竟是整备词典就够、是需要 OCR,还是需要从「查找」转向「提问并获得答案」的思路转变。企业文档「有却用不起来」的状态,从诊断开始,就一定能切实向前推进。
分享这篇文章
相关文章

用AI解决'操作手册无人问津'的难题
深入分析企业内部操作手册不被使用的三大原因,并介绍如何通过AI知识库将'阅读文档'转变为'提问即答'的全新工作方式。

从'搜索'到'提问' -- AI时代企业信息访问的新范式
传统关键词搜索找不到的内部信息,如今只需向AI提问便可即刻获取。本文面向非技术人员,通俗易懂地讲解语义搜索与RAG的原理,介绍企业信息访问的范式转变。

如何将企业'隐性知识'显性化 -- 资深员工离职前必做的事
将资深员工离职时可能流失的隐性知识转化为显性知识,使其成为组织资产。本文以三个步骤详细介绍具体方法。

