
"Gemini 2.5 now supports 1M tokens." "Claude's context window has expanded again." Whenever IT decision-makers see headlines like these, we hear a recurring question:
"Don't we just not need RAG anymore? I heard you can just stuff everything into the prompt and be done with it."
It's true that long-context LLMs (large language models that can read enormous amounts of text in a single shot) have evolved at a remarkable pace, and the claim that "RAG is dead" or "RAG is no longer needed" has become increasingly common on social media and in tech blogs. But a steady stream of companies have stumbled in production by taking that claim at face value.
In this article, we lay out the background behind the "RAG is dead" narrative, then walk through six decision axes for figuring out whether RAG really is unnecessary for your own use case. It's written for IT leaders and executives who are evaluating an internal knowledge AI.
What you'll learn from this article
- The background behind the "RAG is no longer needed" narrative
- The conditions under which RAG genuinely isn't needed (personal or small-scale knowledge)
- Six decision axes that show why RAG is still required for enterprise knowledge use cases
- A decision flow for choosing among long context, RAG, and skill mode
- Where Monoshiri AI fits, and how to avoid making the wrong call when picking an enterprise knowledge AI
Why "RAG Is Dead" Is Being Said Right Now
There are real technical reasons behind the spread of the "RAG is no longer needed" narrative. Let's start by sorting out what has actually changed.
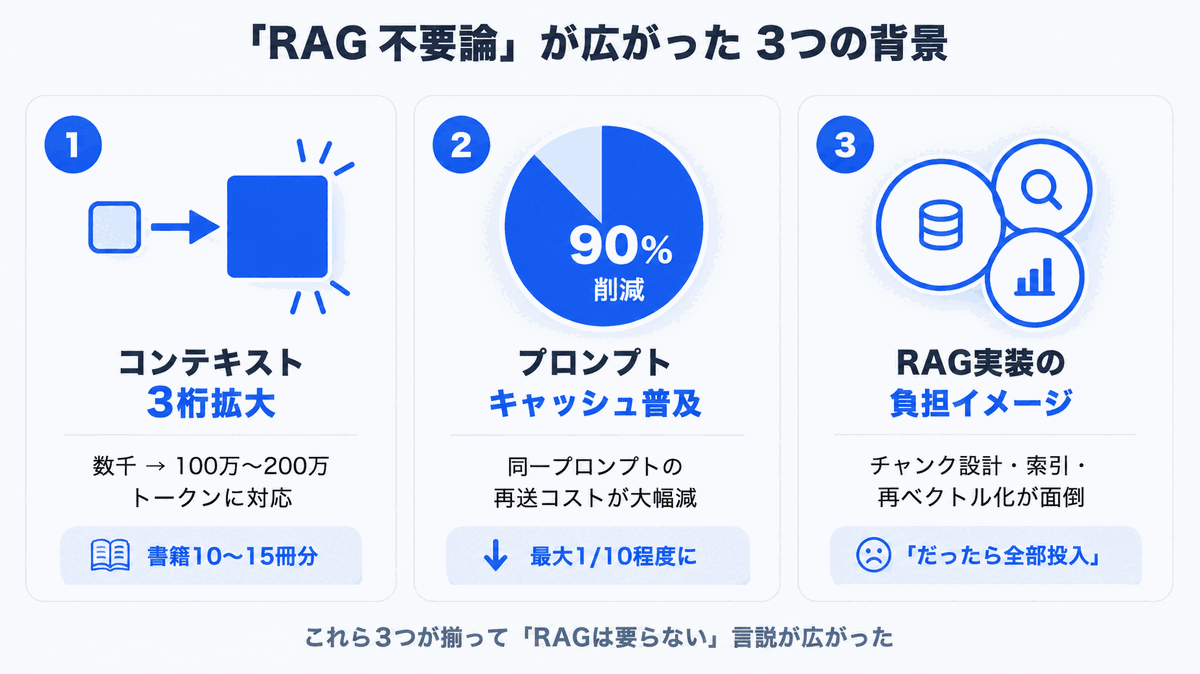
1. Context windows have grown by three orders of magnitude
Just a few years ago, the amount of information a large language model could handle in one shot was on the order of a few thousand tokens (a few thousand characters of English text). From 2024 through 2026, that capacity expanded rapidly, and most of today's leading models support 1 million (1M) to 2 million (2M) tokens.
In English-text terms, 1M tokens is roughly the equivalent of 10 to 15 books. We have genuinely entered an era where you can paste an entire product manual into a single prompt and ask questions against it.
2. Prompt caching has lowered the cost of "feed it everything"
Major LLM providers now offer prompt caching -- a mechanism that discounts the cost of resubmitting the same prompt. As a result, even an operating model that loads a fixed set of internal documents into the prompt every call can shrink the cost of a cache hit to roughly 1/10 of the original.
3. The "RAG is hard to build" reputation has stuck
RAG is conceptually simple, but running it in production requires real expertise:
- Designing how to chunk documents
- Choosing a vector database and designing the index
- Tuning retrieval accuracy (re-ranking, hybrid search, and so on)
- Building a re-embedding pipeline for when documents are updated
Plenty of companies have tried to build all this in-house and burned out. "Skip the messy RAG and just keep things simple with long context" is a perfectly natural impulse.
The Verdict: "RAG Not Needed" Holds Only When Three Conditions Are Met
Let's get the conclusion out of the way. The claim that "RAG is no longer needed" holds only when all three of the following conditions are satisfied:
- The target documents fit within 1M tokens (10 to 15 books or fewer)
- All users are allowed to read the same set of documents (no permission separation needed)
- Document update frequency is low, or you can absorb the cost of regenerating the entire prompt on every update
The textbook examples that satisfy these three conditions are a solo developer asking Q&A against a technical book, an analysis over a few dozen project files, or Q&A against a single product manual.
Conversely, most enterprise internal knowledge use cases trip on at least one of these three conditions. From here on, we'll break down -- across six decision axes -- why enterprises still need RAG.
Six Axes for Deciding Whether Your Company Needs RAG
This is a checklist for cross-checking the "RAG is dead" narrative against your own use case rather than swallowing it whole. If even one of these axes applies to you, running on long context alone should be a red flag.
Axis 1: Document volume -- does your whole corporate corpus fit in 1M tokens at all?
Start by making a rough estimate of how many tokens you'd be looking at if you summed up your entire internal corpus.
| Document type | Approximate token count |
|---|---|
| Employment regulations and HR policies | 50K to 200K |
| Operations manuals (per department) | 100K to 500K |
| Product documentation | Hundreds of thousands to several million |
| Meeting minutes and internal wikis | Several million to tens of millions |
| Customer-support history and tickets | Tens of millions to hundreds of millions |
For a single mid-sized company, the total internal corpus -- including meeting minutes and Slack logs -- routinely lands in the tens of millions to hundreds of millions of tokens. 1M or 2M is nowhere near enough to "feed in everything."
"Then just put the relevant documents into the prompt." But that is exactly the RAG mindset. You're going to need some kind of mechanism to "select the relevant documents" no matter what.
Axis 2: Permission separation -- is everyone allowed to see the same documents?
Enterprise knowledge bases routinely have access rights that vary by user and by department:
- Salary and performance-evaluation files visible only to HR
- Financial records visible only to accounting
- Confidential materials limited to project members
- Strategy materials limited to executives
In a long-context setup, you'd need to assemble a different set of documents into the prompt for each user. That introduces three problems:
- Cache efficiency degrades: prompts vary per user, so prompt-cache hit rates drop
- Permission logic gets entangled: "is it OK to include this?" decisions leak into the prompt-assembly layer
- Information-leak risk: a single permission-check mistake leads directly to a confidential-data leak
RAG, where you can filter by user permissions at the retrieval stage, is a far cleaner design. This isn't really a tech-stack debate; it's a basic principle of enterprise information systems.
Axis 3: Update frequency -- how often do your documents change?
Internal documents are anything but static. Policy revisions, new product launches, additional meeting minutes, FAQ updates -- something changes every day.
| Approach | What happens when one document is added |
|---|---|
| RAG | Just the new content is embedded and registered to the index (a few seconds) |
| Long context, full dump | The entire prompt is rebuilt and the cache is regenerated |
Whether you can update incrementally or not has a direct impact on operational cost. In environments where documents are updated daily or hourly, RAG's edge isn't going anywhere.
Axis 4: Query frequency -- how many questions hit the system per day?
An internal knowledge AI sees query volume rise the more it gets adopted. You might start at a few dozen queries per day; once it sticks, you can easily reach hundreds or thousands per day.
What matters here is the input token count per query. Suppose you're loading 1M (one million) tokens of internal documents into the prompt:
- Per query: a few cents to a few dollars (depending on the model)
- At 1,000 queries per day: thousands to tens of thousands of dollars per month
- Even with prompt caching, the very first call and the re-cache after each update still cost the full price
With RAG, you only send the relevant chunks -- typically a few thousand to tens of thousands of tokens per query. The cost gap is, quite literally, an order of magnitude.
Axis 5: Pinpoint accuracy -- can you tolerate "Lost in the Middle"?
It's easy to assume "long context will read everything carefully," but multiple studies have shown that LLMs strongly attend to the beginning and end of the prompt and tend to drop information sitting in the middle. The phenomenon is known as "Lost in the Middle."
- The accuracy drop is especially noticeable on pinpoint factual questions ("What's the deadline for filing X?")
- Degradation accelerates as the prompt gets longer
- Even models advertised as 1M-capable, in practice, are reported to maintain real precision only up to a few hundred thousand tokens
For "pull a specific sentence" tasks, RAG -- which sends only the few relevant pages -- is more reliable in practice.
Axis 6: Audit and accountability -- can you show "why the AI answered that way"?
When AI is used for business work -- especially in departments like legal, HR, and accounting where accuracy is the foundation of the job -- it's critical to be able to trace "which document and which passage the AI used as evidence" after the fact.
- Long context, full dump: all you can say is "I read everything"; the source of any specific claim is fuzzy
- RAG: you can cite the specific chunks that the search returned
- Skill mode (introduced below): the path the AI followed through the table of contents is preserved as a history
The more your use case demands audit and accountability, the more "evidence traceability" becomes the single most important axis in your technology selection.

Which Approach Should Your Organization Pick? -- A Decision Flow
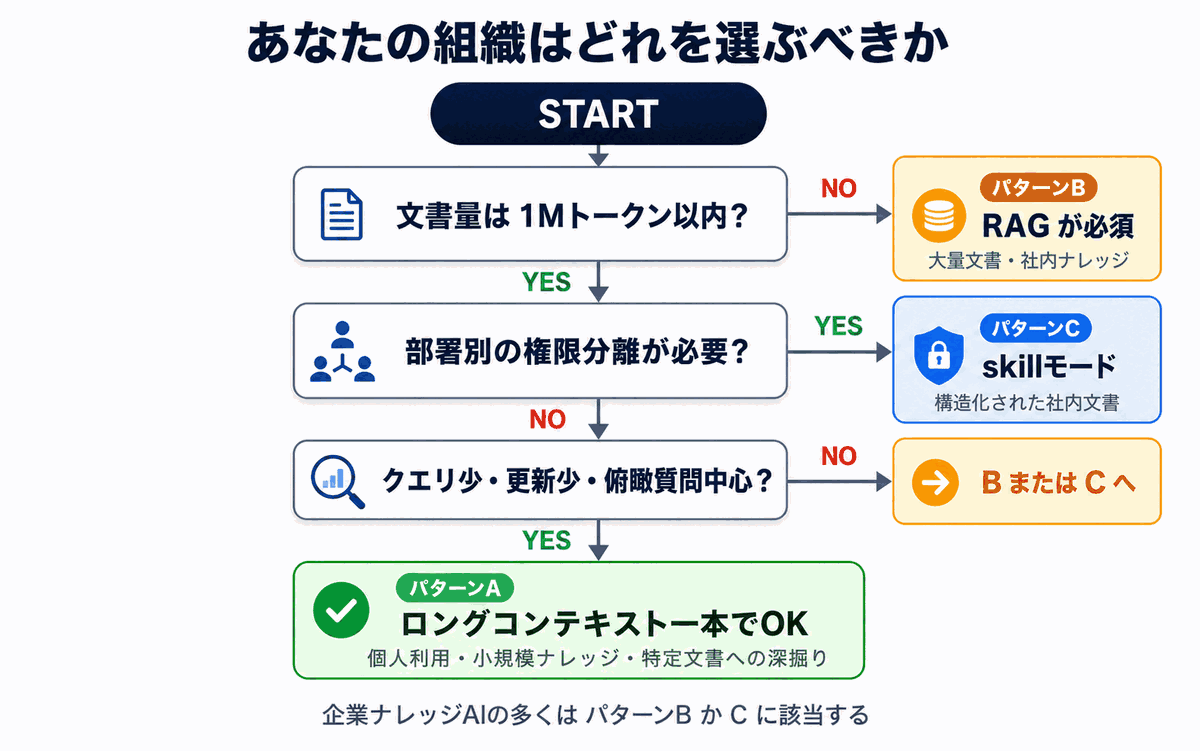
Building on the axes above, here's a decision flow for picking the approach that fits your own use case.
Pattern A: Long context alone is fine
If all of the following apply, running on long context without RAG is enough.
- Target documents fit within 1M tokens (e.g. one product manual, a few contracts, the minutes of a single project)
- All users may read the same documents
- Documents are updated at most a few times per month
- Query volume is no more than a few dozen per day
- Questions center on "overview-style analysis of the whole document"
Typical use cases: personal use, analysis over small knowledge sets, and deep-dive questions against a specific document
Pattern B: RAG is essentially required
If any of the following apply, RAG (or some equivalent retrieval-style approach) is essentially required.
- Document volume exceeds thousands of files or millions of tokens
- You need permission separation by department or by project
- Documents are added or updated at least daily
- The whole company asks questions routinely (high query volume)
- Questions are mostly pinpoint -- "what does article X of regulation Y say?"
Typical use cases: enterprise internal knowledge bases, customer-support FAQs, product-documentation search
Pattern C: A third path optimized for internal knowledge
In reality, for enterprise internal knowledge use cases, the binary "RAG vs. long context" framing often fails to deliver an answer.
- RAG is strong on large corpora, but residual hallucination risk remains
- Long context gets stuck on cost and permission separation
- You want the best of both worlds
The approach that has been gaining attention recently is one that leverages the inherent chapter / section / item structure of the documents themselves. Skill Mode (Corpus2Skill) -- the approach Monoshiri AI uses -- is the canonical example: the AI is handed a "table of contents" and is allowed to go read the documents it actually needs by itself.
For the full technical decision log and the migration story, see RAG Wasn't Enough -- Why Monoshiri AI Switched to Skill Mode.
Common Misconceptions and How to Frame Them Correctly
The "RAG is dead" narrative often carries some misconceptions. Here are the most common ones.
Misconception 1: "Once context windows get big enough, retrieval becomes unnecessary"
The reality: No matter how much the context window grows, the volume of corporate documents continues to grow even faster. Permission separation, cost, and Lost in the Middle aren't problems that go away when the context window expands.
Misconception 2: "RAG hallucinates too much to be useful"
The reality: Hallucinations are an issue of RAG's design and operation. With proper retrieval accuracy, explicit source citations, and a design that returns "no matching record" when there is none, hallucinations can be kept under control. The right move is to acknowledge RAG's structural weaknesses and pick complementary approaches (hybrid setups, skill mode, etc.) on top of it.
Misconception 3: "Long context never hallucinates"
The reality: Lost in the Middle still causes information in the middle of long prompts to be dropped. "I fed in everything, so it's perfect" simply isn't true.
Misconception 4: "RAG is mature and won't evolve any further"
The reality: The space around RAG is still evolving fast. New-generation derivatives like Agentic RAG, Cache-Augmented Generation, and Corpus2Skill keep appearing. The right framing isn't "RAG is dead" -- it's "the shape of RAG is evolving."
Where Monoshiri AI Stands -- Beyond "RAG vs. No RAG"
Monoshiri AI itself evaluated RAG, long context, and hybrid setups when we launched the service. The conclusion we reached was Skill Mode (Corpus2Skill) -- a design that fully exploits the structure inherent to internal knowledge (the chapters and hierarchies of regulations, manuals, and FAQs).
Skill Mode is optimized for enterprise knowledge use cases on the following points:
- Accuracy: by navigating from a table of contents, hallucinations from missed retrieval are far less likely
- Cost: only the documents that actually need reading are read, so you avoid the cost explosion of a full long-context dump
- Permissions: it lines up cleanly with folder-level access control
- Updates: when new documents are added, the table of contents is updated automatically
- Audit: a history of "which document and which section was read" is preserved
In other words, Monoshiri AI's stance is not "RAG is dead" -- it's "we use a method, specialized for internal knowledge, that goes beyond both RAG and long context."
You can see Monoshiri AI's core capabilities on the Features page, and our pricing on the Pricing page. For a side-by-side with other AI knowledge SaaS, see the Comparison page.
Three Steps to Take Before Deciding "Do I Need RAG?"
Finally, here are the practical steps for actually deciding "RAG: needed or not needed?" for your own organization.
Step 1: Estimate document volume
Calculate -- roughly is fine -- the total token count of your internal corpus. total characters / 1.5 gives you a rough token count for English. The first fork in the road is whether or not you fit within 1M tokens.
Step 2: Lay out your permission requirements
Build a table of who is allowed to access which documents, broken down by department, by role, and by project. If even one row requires separation, running on long context alone is dangerous.
Step 3: Estimate your query volume and cost
Multiply your projected number of users after rollout by their daily query count, and compare the monthly cost across long context, RAG, and skill mode. The bigger you scale, the wider the gap gets.
Summary
In this article, we put the "RAG is dead" claim through six decision axes. To recap:
- "RAG no longer needed" holds only for personal or small-scale knowledge use cases that satisfy all three conditions: document volume, permissions, and update frequency
- Most enterprise internal knowledge use cases need a RAG-style mechanism on at least one of these six axes: document volume, permissions, updates, query volume, pinpoint accuracy, and audit
- "RAG vs. long context" isn't a binary -- the realistic answer is to use them in the right places, or to integrate them
- For internal knowledge specifically, there's also a third path beyond both: skill mode (Corpus2Skill)
- Make the call on the basis of estimates -- document volume, permissions, query volume, and cost -- not gut feel
The catchy "RAG is dead" line captures only one slice of the AI trend. Whether it fits your own use case can only be decided by your own document volume and your own requirements. We hope the six axes above give you a useful starting point for that decision.
Related articles
- What Is RAG? A Plain-Language Guide to Transforming Internal Document Search
- Is RAG Obsolete? Designing Knowledge Bases in the Long-Context Era
- RAG Wasn't Enough -- Why Monoshiri AI Switched to Skill Mode
- How to Search Internal Documents with AI -- Differences from Keyword Search and Steps to Roll Out
Share this article
Related Articles

What Is Corpus2Skill? RAG vs. Skill Mode Explained
"What if the AI lies?" "It can't handle complex questions." Learn how Monoshiri AI tackled RAG's hallucination problem and retrieval limits by moving to Skill Mode, with concrete examples.

What Is RAG? A Plain-English Guide to the Technology Reshaping Internal Document Search
A non-engineer's guide to RAG (Retrieval-Augmented Generation). Covers the limits of traditional internal document search, the changes RAG brings, and key points for enterprise adoption.

Is RAG Obsolete? Designing Knowledge Bases in the Long-Context Era
With 1M-token long-context models on the rise, some say RAG is no longer needed. We examine the claim from five angles -- cost, capacity, permissions, accuracy, and updates -- and show the current best answer for enterprise knowledge bases.
Try Monoshiri AI for free
Just upload your documents and start asking AI. Try our free plan with unlimited users.
Get Started FreeNo credit card required / Start in 1 minute