
"RAG is obsolete. Just dump everything into a 1M-token context and you're done." Debates along these lines have become increasingly common in the AI community. As major generative models adopt ever-longer context windows one after another, we have entered an era where in theory you can load an entire corpus of internal documents into a single prompt and ask questions against it.
So does that mean RAG (Retrieval-Augmented Generation) is no longer needed? In this article we take the question head-on and explain -- with technical reasoning and concrete numbers -- why, for enterprise knowledge base use cases, "picking the right approach for the right job is the best answer we have today."
What You'll Learn
- The long-context revolution and why the "RAG is obsolete" argument appeared
- Five walls that the "just feed it everything" approach hits in an enterprise knowledge base
- The areas where long context genuinely shines
- The hybrid approach as a pragmatic answer, and the decision axes to use when designing
The Long-Context Revolution -- "Read Everything" Becomes Real
Over the past year or two, the context window of large language models (LLMs) -- the volume of information they can handle in a single exchange -- has expanded dramatically.
- Major generative models now handle long contexts on the order of 1 million (1M) to 2 million (2M) tokens
- In Japanese text terms, 1M tokens is roughly 3,500 manuscript pages, or 10 to 15 books
- More and more models can multimodally ingest images, tables, and PDFs
This is a scale that was unimaginable just a few years ago. Given that the context window of GPT-3 (2020) was around 4,000 tokens, we're looking at nearly three orders of magnitude of scale-up.
Riding this rapid evolution, a natural voice started rising from the AI community: "If it can read that much, why bother with RAG? Just shove all the internal documents into the prompt."
For the mechanics and core concepts of RAG itself, see What Is RAG?. This article builds on that foundation to weigh the merits of the "RAG is obsolete" argument.
The Reality of "Just Feed It Everything" -- Theory vs. Practice
To cut to the conclusion: for personal use or small document collections, dumping everything into a long context is a perfectly viable approach. But once you turn to enterprise knowledge base use cases, you run into one wall after another. Let's look at five of the most representative ones.
Wall 1: Cost -- Are You Really Going to Send 100MB with Every Query?
The biggest drawback of long context is cost. Tokens placed into the prompt are, as a rule, billed every single call.
Imagine a company that has 100MB of internal documents (roughly 50MB of raw text, or about 25 million characters). In tokens, that comes to roughly 16 million tokens. It won't fit in today's 1M context, but let's assume future windows stretch to 2M, 5M, and beyond.
| Scenario | Input tokens per query | Cost per query (ballpark) | Monthly cost at 10,000 queries |
|---|---|---|---|
| RAG (only the relevant chunks) | A few thousand to tens of thousands | A few cents or less | A few hundred dollars |
| Long context, full dump | 1M to 16M | Several dollars to tens of dollars | Tens of thousands to hundreds of thousands of dollars |
Prompt caching (a mechanism that discounts repeated submissions of the same prompt) can compress the cost of cache hits down to roughly 1/10 of the original. Even so, a daily bill running into the thousands of dollars doesn't vanish easily. It's also worth remembering that the first call that populates the cache -- and any re-caching after documents are updated -- still costs full price.
The order of magnitude of cost is literally different between "RAG, which sends only the handful of pages that are relevant" and "long context, which sends everything every time."
Wall 2: Capacity -- Even 1M to 2M Tokens Won't Hold a Mid-Sized Company's Docs
There's also a simpler problem: does a long context actually have room for all of a company's documents?
- 1M tokens is roughly 10 to 15 books
- A single mid-sized company typically holds 1,000 to 5,000 PDFs, amounting to tens of millions to hundreds of millions of tokens
- Once you include meeting minutes, Slack logs, and customer emails, that figure easily jumps by another order of magnitude
In other words, 1M to 2M tokens simply isn't enough to "feed in everything." Long context is undeniably a major step forward, but as a "storage layer for all of corporate knowledge" it is still small.
Wall 3: Permission Separation -- Not Everyone Can See the Same Documents
Enterprise knowledge bases operate on the fundamental premise that access rights differ by user and by department.
- Compensation and performance-review materials visible only to HR
- Confidential files tied to specific projects
- Strategy materials limited to executives and senior management
In a long-context approach, you would, in theory, need to assemble a different set of documents into the prompt for every user. That introduces several issues:
- Caches fragment per user, eroding cost efficiency
- Permission-check logic leaks into the prompt-assembly layer, making the design more complex
- A single mistake in "is it OK to include this?" becomes an information leak
For enterprise use cases built around permissions and access control, RAG is far more natural, because you can filter at the retrieval stage. You can see how Monoshiri AI, an AI knowledge base for internal documents, implements folder-level access control in our Security Policy.
Wall 4: Lost in the Middle -- Accuracy Drops as the Context Gets Longer
It's tempting to assume "if I put it in the long context, the model will read it properly." In practice, multiple studies have shown that LLMs pay much more attention to the beginning and end of the prompt and tend to drop information in the middle. This phenomenon is known as "Lost in the Middle."
- The degradation is especially noticeable on pinpoint questions that retrieve a single fact ("What's the deadline for filing X?")
- Accuracy drops accelerate as document count and length grow
- Some observations suggest that even models advertised as 1M-context can only handle a few hundred thousand tokens with real precision
RAG places only a handful of highly relevant pages into the prompt, which makes it structurally resistant to Lost in the Middle. For the task of "pulling one specific sentence out of a large document set," RAG is actually the stronger approach.
Wall 5: Updates -- What Happens Every Time You Add One Document?
Corporate knowledge gets updated every day. Policy revisions, new product launches, additional meeting minutes. Let's compare what happens each time a single document is added.
| Approach | What happens when a document is added |
|---|---|
| RAG | Just the new chunk is embedded and added to the index |
| Long context, full dump | The entire prompt is rebuilt, and the cache has to be regenerated |
Whether you can process just the delta is a crucial point that directly affects operational cost. RAG handles incremental updates gracefully; dumping everything into long context does not -- a clear structural difference.
Where Long Context Genuinely Shines
Up to this point we've highlighted the challenges of long context, but this is not an argument that it's useless. On the contrary, long context is overwhelmingly powerful in the exact areas where RAG struggles.
1. Small, Self-Contained Knowledge
For knowledge bases that consist of just a handful of documents, dumping everything into long context is the fastest and strongest approach. For Q&A against a single product manual, a single contract, or a single set of minutes, pasting the text directly into the prompt is quicker and more reliable than building a retrieval index.
2. Deep Reasoning and Cross-Referencing Within a Document
Tasks like "point out the contradictions between Chapter A and Chapter B in this long document" or "summarize the whole thing" require seeing the entire document at once, which puts RAG's chunked approach at a disadvantage. This is long context's home turf.
3. Integrated Analysis Across Multiple Documents
Cross-cutting analyses like "extract the patterns common to these 10-30 related documents" are also a good fit for long context.
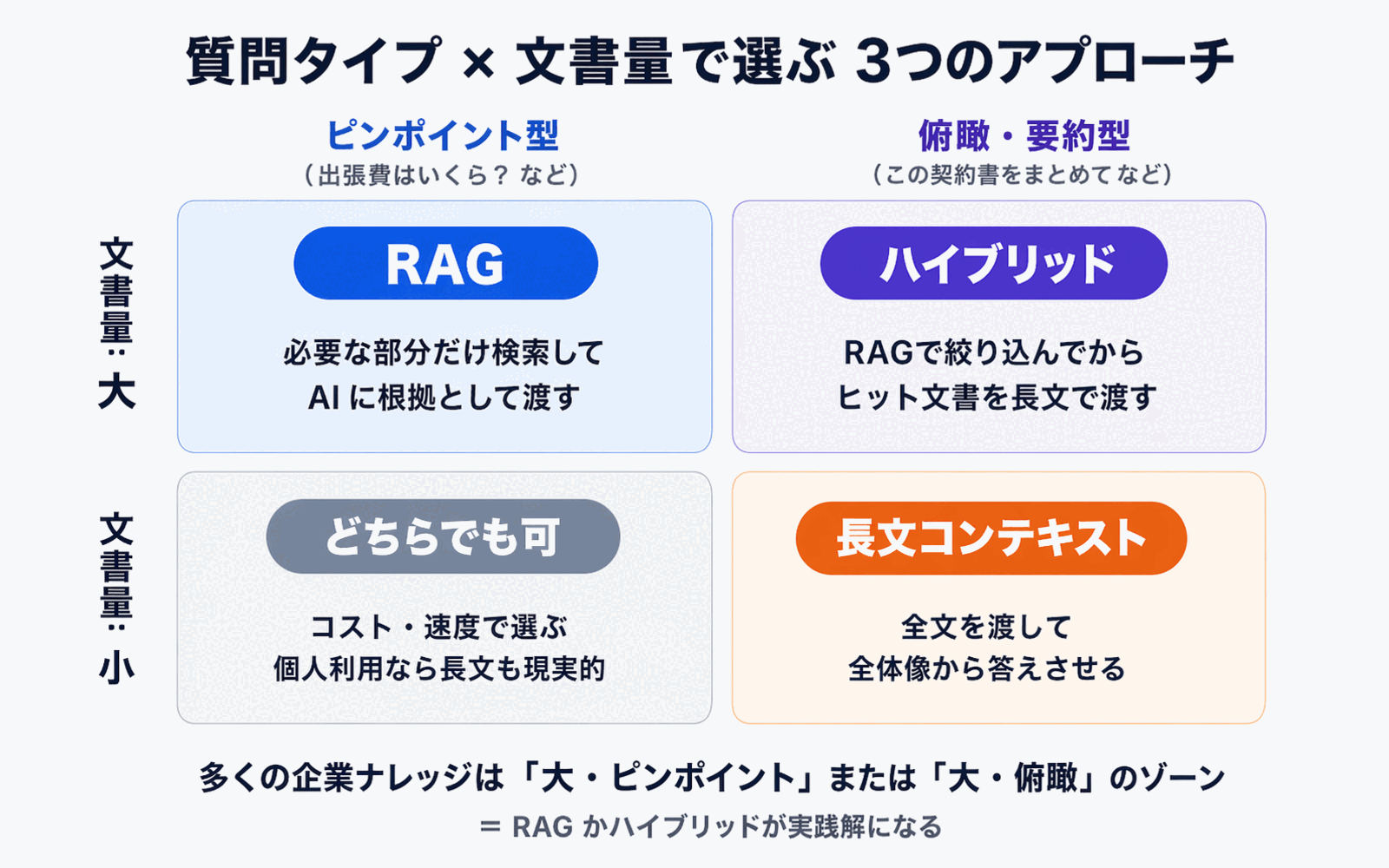
Pinpoint-retrieval tasks favor RAG; whole-document overview tasks favor long context -- framed this way, the division of labor becomes clear.
The Practical Answer Is Hybrid -- Three Approaches to Combine
Given these characteristics, real-world designs are increasingly landing on a combination of the following three approaches.
1. Classical RAG -- The Foundation for Search-and-Answer on Large Knowledge Bases
Traditional RAG remains the most cost-effective option for the classic use case of "pulling just a few pages out of a large corpus to produce an answer." For the mechanics of semantic search itself, see How to Search Internal Documents with AI.
2. Using Long Context -- For Small-Scale or Deep-Dive Tasks
When the target document set is already narrowed down and you need deep reasoning within those documents, leaning directly on long context is the shortest path.
3. Hybrid Approaches (Agentic RAG / RAG + Long Context / CAG)
The approach attracting the most attention lately is the hybrid. Notable variations include:
- Agentic RAG: An AI agent autonomously decides to "search first → search again if needed → pull up the full document if necessary"
- RAG + Long Context: Use RAG to narrow down to a relevant set of documents, then load each of those documents whole into long context (reducing the downsides of aggressive chunking)
- Cache-Augmented Generation (CAG): Pre-load frequently used documents into the prompt cache to skip the retrieval step while keeping costs under control
The right way to think of these is not "RAG or long context" but designs that integrate the two.
4. Corpus2Skill -- Use the Document's Own Structure as Navigation
A fourth direction has been gaining attention recently: let the LLM navigate the chapter / section / item structure that documents already carry, using it as a tool. The leading example is Corpus2Skill (skill mode), which Monoshiri AI now uses.
This is distinct from RAG, long context, and the hybrid above. Instead of pushing content into a vector space, it uses the document structure that was already organized for human readers as a semantic table of contents. Citations are always hierarchical, and there is no re-embedding operational load. It's strong against mid-sized, structured corpora (policies, manuals, FAQs) and pairs well with prompt caching.
We arrived at this design after evaluating RAG, long context, and hybrid in production ourselves. The full technical decision log is in We Left RAG -- Why Monoshiri AI Migrated Entirely to Corpus2Skill (Skill Mode).
Five Decision Axes for Designing an Enterprise Knowledge Base
So what criteria should you use when designing your own knowledge base? We recommend organizing the decision around these five axes.
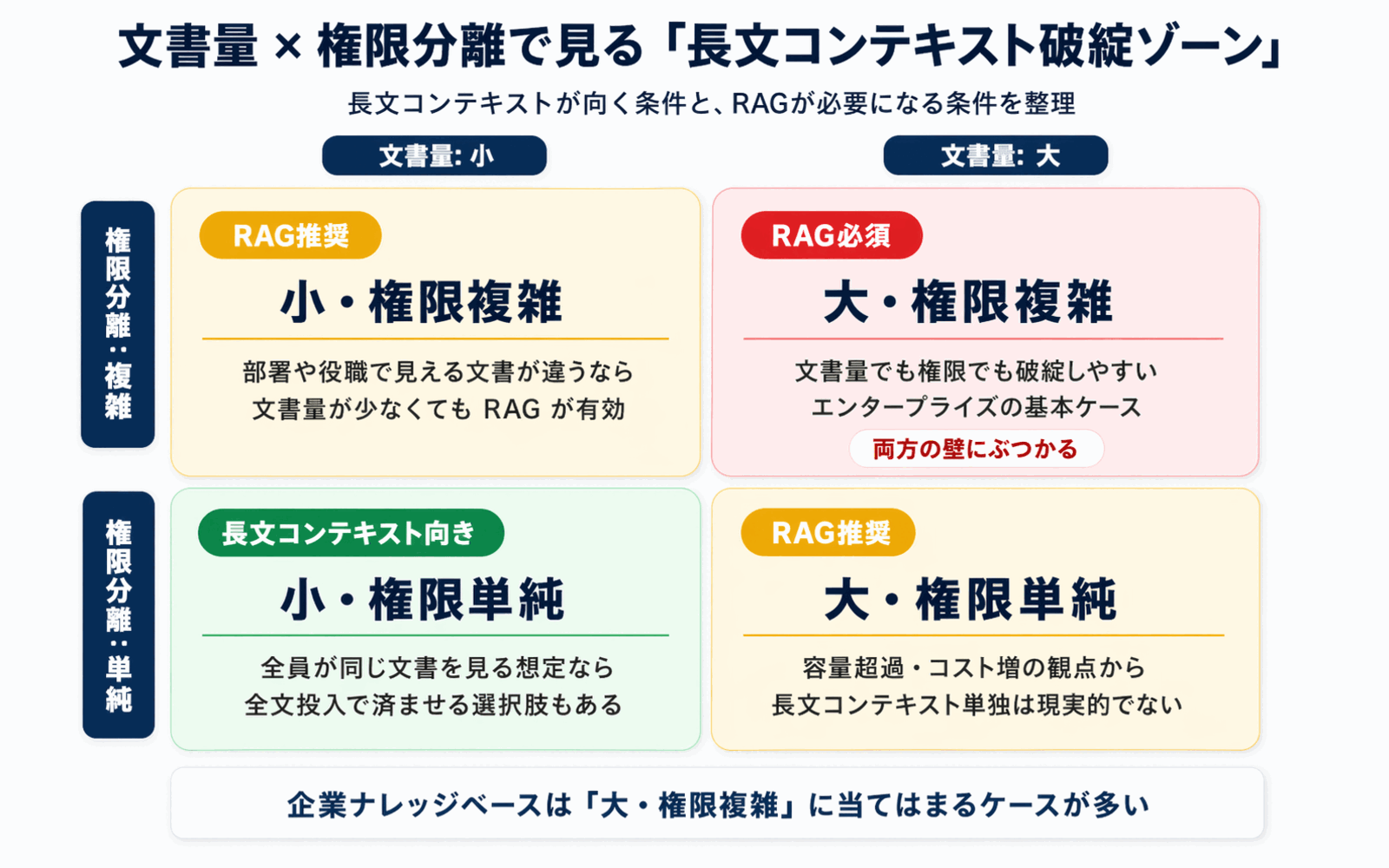
1. Document Volume
| Scale | Recommended approach |
|---|---|
| A handful to a few dozen documents | Long-context centric |
| Hundreds to thousands of documents | RAG centric, hybrid where needed |
| Tens of thousands or more | RAG required |
2. Permission Separation Requirements
If you need to distinguish access rights by department or job level, a RAG-style approach that filters at the retrieval stage is effectively a must-have.
3. Update Frequency
In environments where documents are added or updated daily -- or hourly -- RAG's strength in incremental updates makes operations significantly easier.
4. Cost Tolerance
If query volume is high (for instance, the whole company uses it every day), a long-context setup that sends massive token counts on every call can quickly consume the budget. Estimate carefully.
5. Question Type
- Mostly "pull a specific fact" questions → RAG is the stronger fit
- Mostly "get an overview of the whole document" questions → long context is the stronger fit
- A mix of both → hybrid
We hit the same question ourselves and -- after evaluating RAG, long context, and hybrid in production -- arrived at a fourth option that leverages the inherent structure of internal documents: Corpus2Skill (skill tree). The full technical decision log is here. For pricing, see our Pricing page, and for our core capabilities, see the Features page.
Summary
This article tackled the "RAG is obsolete" argument in the long-context era and laid out design principles for enterprise knowledge bases. To recap the main points:
- Long context is genuinely revolutionary, but for enterprise knowledge base use cases it hits five walls: cost, capacity, permissions, accuracy, and updates. "Just feed it everything" works for personal use and small document sets, but not yet for a full enterprise corpus
- RAG and long context are complementary, not adversarial: RAG is strong at pinpoint retrieval; long context is strong at whole-document overviews
- The practical answer is hybrid: Agentic RAG, RAG + Long Context, Cache-Augmented Generation, and similar designs that integrate the two are becoming mainstream
- Use five decision axes when designing: document volume, permission separation, update frequency, cost tolerance, and question type. Organize your own requirements along these axes and the right answer starts to reveal itself
AI technology moves fast, and it's entirely possible that a few years from now today's conventional wisdom will have been rewritten again. Even so, the skill of asking "which technology fits my own use case best?" is just as important in any era. We hope this article gives you a useful starting point for that judgment.
Share this article
Related Articles

Is "RAG Is Dead" Really True? 6 Criteria for Internal Knowledge AI
With long-context LLMs on the rise, many claim "RAG is no longer needed." We sort out the cases where it genuinely isn't, and the cases where RAG is still essential, using six decision axes for choosing an internal knowledge AI.

What Is Corpus2Skill? RAG vs. Skill Mode Explained
"What if the AI lies?" "It can't handle complex questions." Learn how Monoshiri AI tackled RAG's hallucination problem and retrieval limits by moving to Skill Mode, with concrete examples.

What Is RAG? A Plain-English Guide to the Technology Reshaping Internal Document Search
A non-engineer's guide to RAG (Retrieval-Augmented Generation). Covers the limits of traditional internal document search, the changes RAG brings, and key points for enterprise adoption.
