
"We want AI to answer questions about our internal documents, but what if it lies?" "Search misses the mark when the question gets complex." These are the most common concerns we hear from customers evaluating an AI knowledge base.
Like many other AI services, Monoshiri AI initially relied on RAG (Retrieval-Augmented Generation). But as we kept running it in production, we realized that RAG's structural limits were unacceptable for our customers' real workflows. So in April 2026, Monoshiri AI fully migrated to a new approach we call Skill Mode (Corpus2Skill).
In this article, we explain why RAG alone struggles to answer certain questions, and what Monoshiri AI now promises customers with Skill Mode, illustrated with real-world scenarios.
What you'll learn from this article
- The structural reason why RAG produces hallucinations (false answers)
- Why RAG is weak with large document sets and questions that span multiple items
- Three problems Monoshiri AI solved by moving to Skill Mode
- How RAG and Skill Mode answers actually differ in real internal-knowledge use cases
1. Why RAG "Lies"
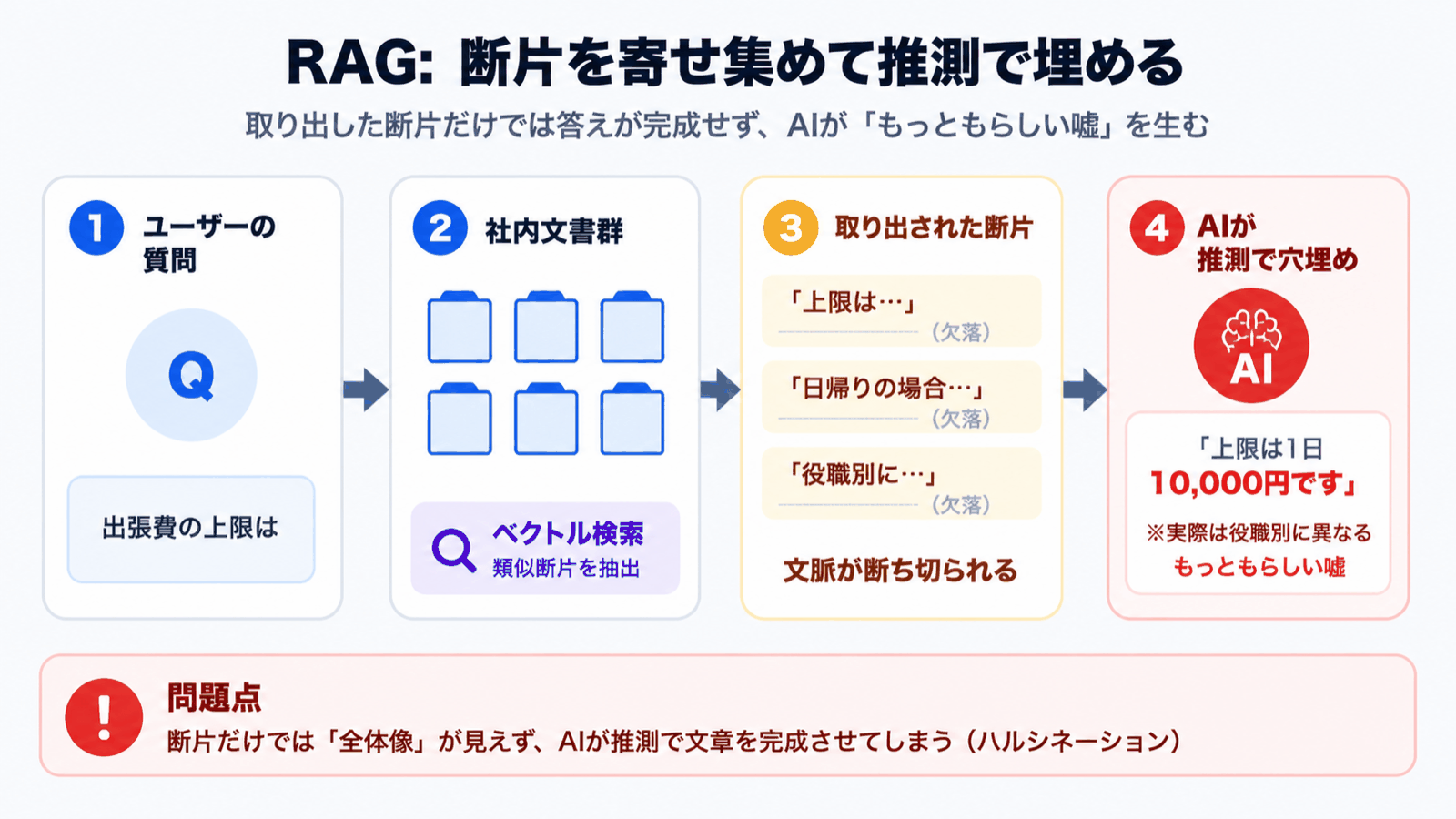
RAG works roughly like this:
- Documents are split into small fragments (chunks) and pre-vectorized
- The user's question is also vectorized, and just a handful of similar fragments are retrieved
- Those fragments are handed to the AI, which composes an answer from them
It's simple and powerful, but the design of "retrieve only a few" and "answer only from those" is exactly what breeds hallucination.
Common failure patterns
- The most relevant fragment never makes it into the top search results -- the AI tries to answer using only what it has, and fills the gaps with guesses
- Critical information gets cut at chunk boundaries -- table headers and values, or the premises and exceptions of a regulation, end up in different chunks, so the AI receives broken context
- The answer doesn't exist anywhere in the documents -- the AI looks at the search results and confidently fabricates something that sounds right
In other words, RAG is a system where the quality of the search results directly determines the quality of the answer. The moment search misses, the AI lies without hesitation. For our customers, that was a deal-breaker.
In departments like legal, HR, and accounting where accuracy is non-negotiable, "we can't trust the AI's answer enough to act on it" is the single biggest reason adoption stalls.
2. Three Limits Monoshiri AI Hit Head-On
Monoshiri AI is a knowledge base SaaS focused on internal regulations, manuals, and FAQs. Running RAG in production, we hit walls in three specific scenarios.
Limit 1. It can't answer questions that span multiple documents
Consider a question like:
"Compare our employment regulations and HR evaluation policy -- how does the frequency of evaluation interviews differ?"
This requires reading both documents simultaneously and comparing them. But because RAG is designed to "retrieve a few fragments closest to the question," it often picks fragments from one document and ignores the other entirely. The result is either an answer that only covers one side and never delivers the comparison, or worse: the AI fabricates "the HR evaluation policy says X" as a hallucination.
Limit 2. It can't narrow down across large document sets
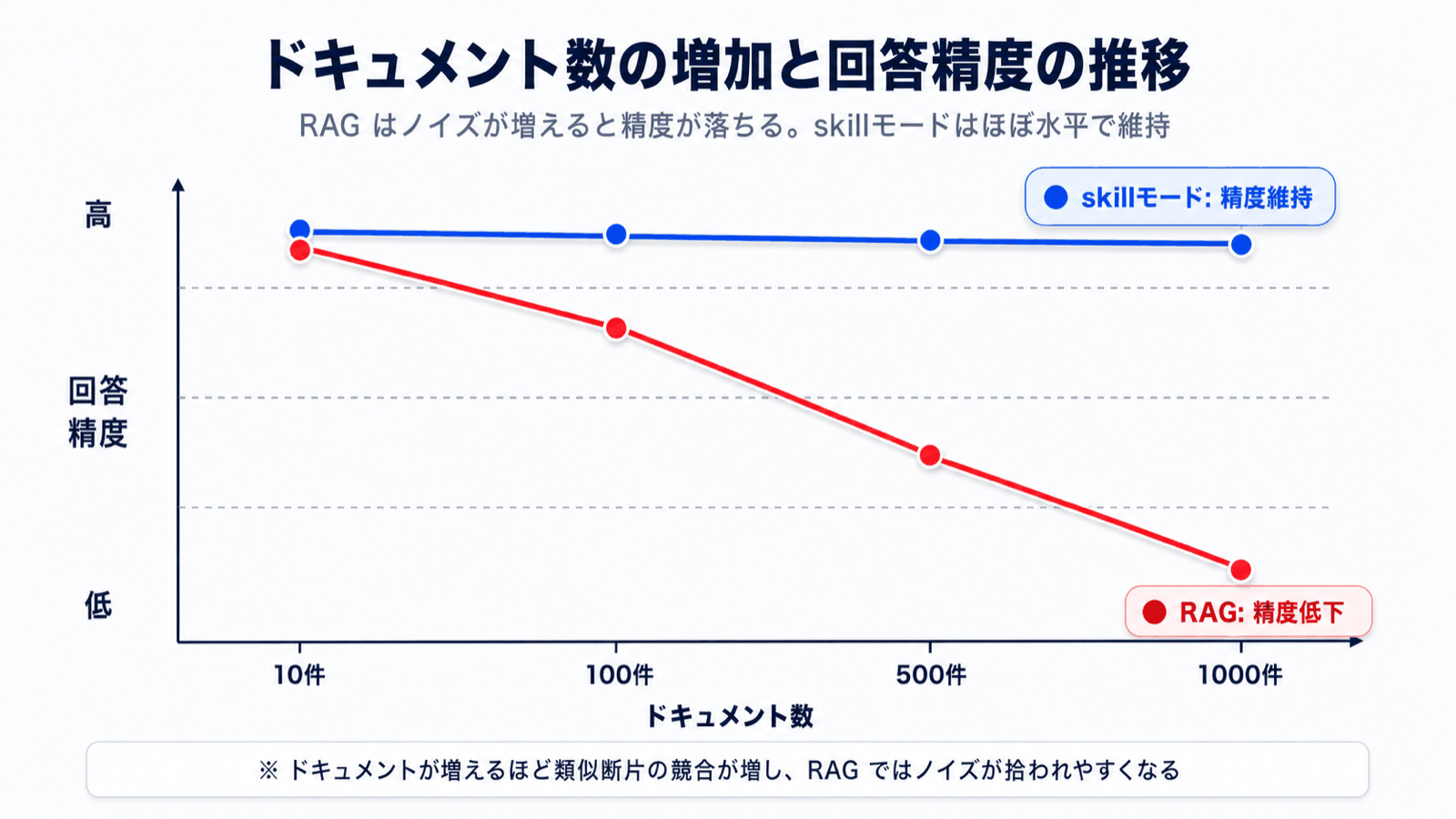
As your knowledge base grows to 100, 300 documents, retrieval accuracy degrades, guaranteed. Why?
- More documents mean similar phrasings scatter across many files
- Fragments with "similar relevance scores" pile up, burying what you actually need
- When the user's question is abstract, off-target fragments get mixed in easily
You hit a paradox: the more documents you accumulate, the dumber the AI gets. Internal knowledge inevitably grows over time, so this struck at the very foundation of operations.
Limit 3. It can't honestly say "I don't have that information"
The trickiest one is handling questions for which no document holds the answer.
"How do I issue an API key?" (when no such document exists in the knowledge base)
Because RAG always "pulls the closest fragment," it returns something even when nothing is genuinely relevant. The AI then sees that and replies with a plausible-sounding lie like "API keys can be issued from the admin panel."
Being unable to say "no information available" when there is none is fatal for business use.
3. Monoshiri AI's Answer: Skill Mode
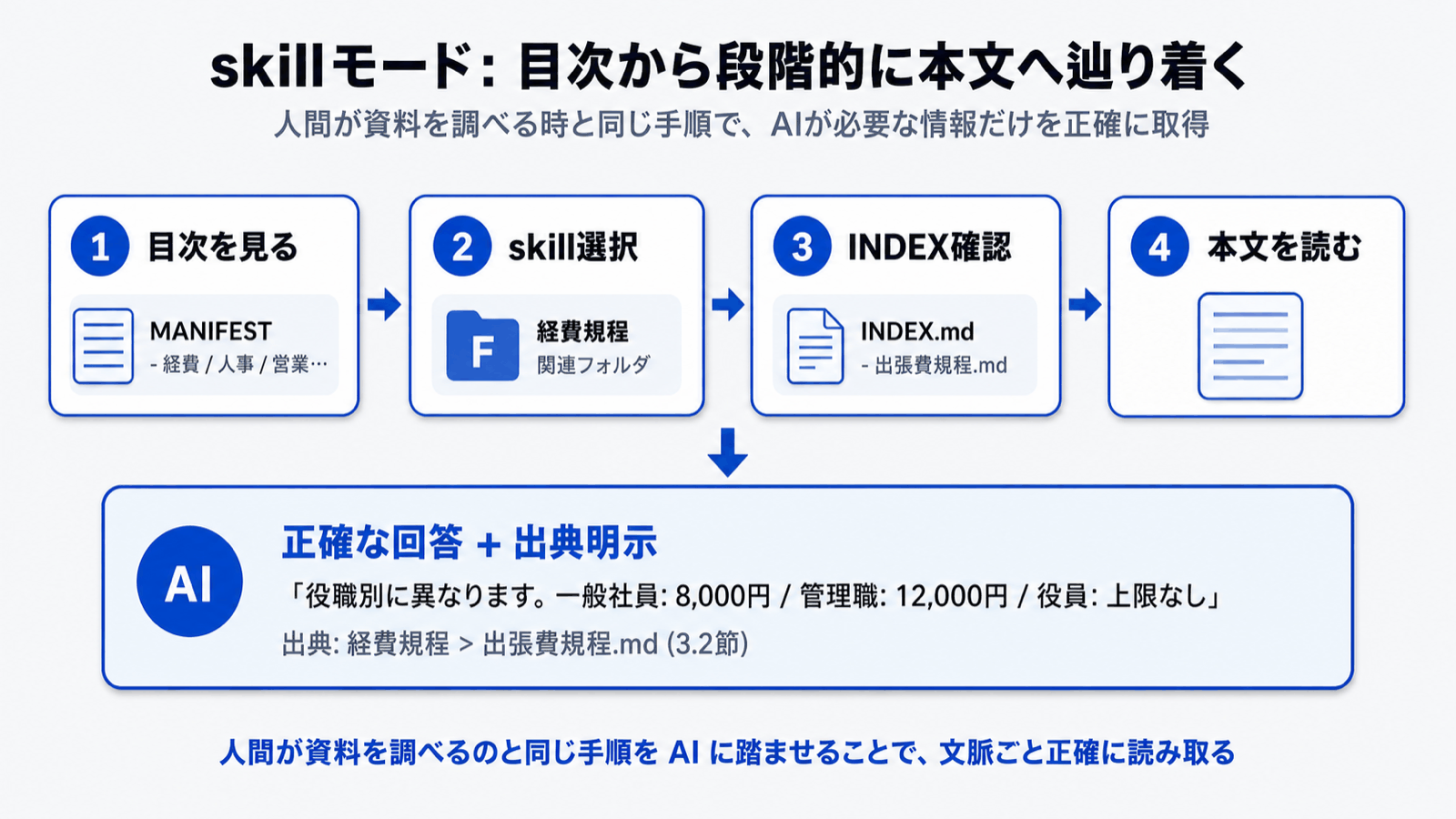
To overcome these limits, Monoshiri AI adopted Skill Mode (Corpus2Skill).
In one sentence:
A method that hands the AI a "table of contents" and lets it go read the documents it needs by itself.
Where RAG searches and feeds back results, Skill Mode navigates from a table of contents and reads the source text -- the same process a human would follow when consulting reference material.
What changes from the customer's perspective
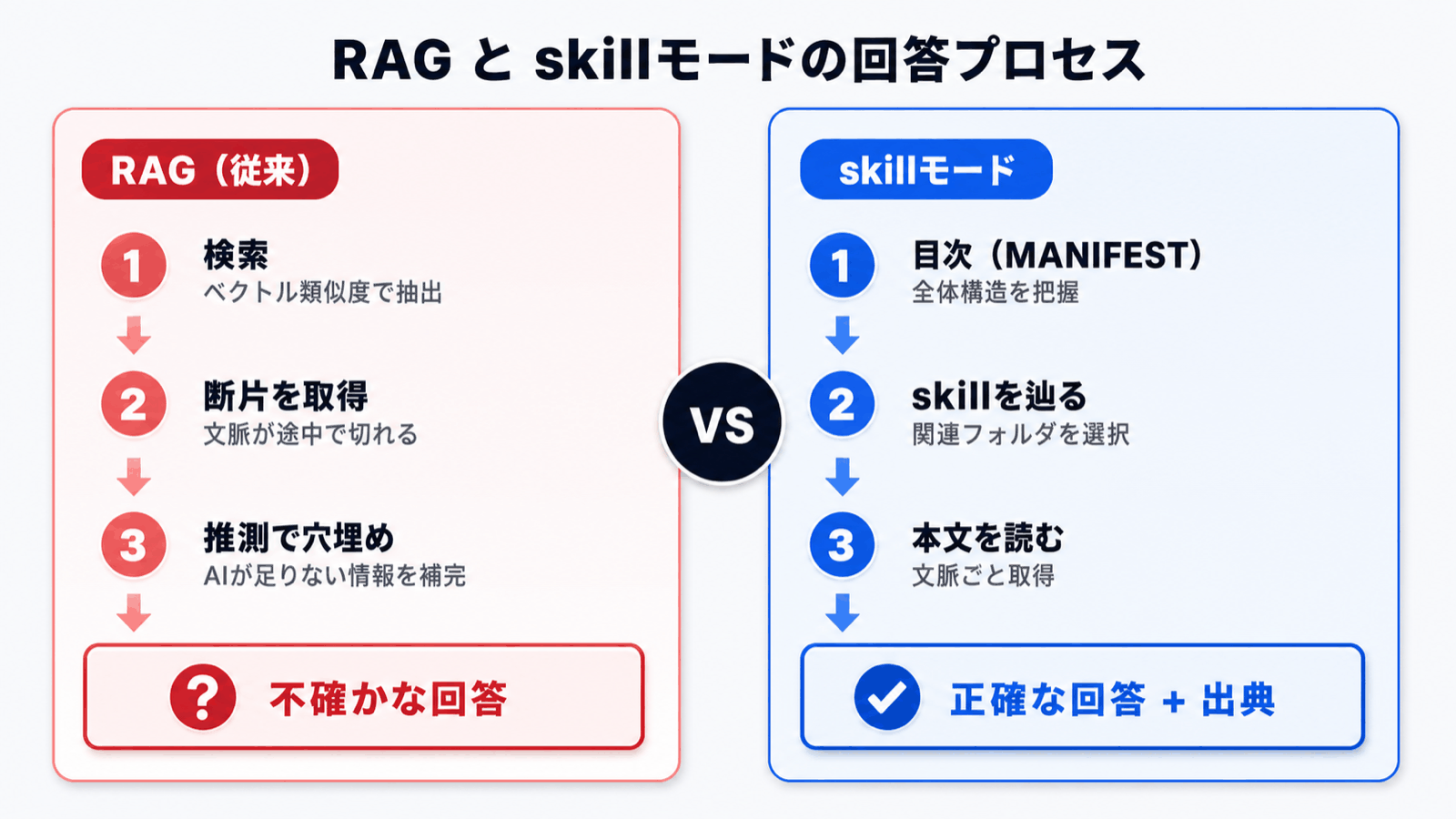
| Aspect | RAG | Skill Mode |
|---|---|---|
| Source of the answer | A few retrieved fragments | The full documents the AI actually read |
| Risk of lying | Fabricates when search misses | Can answer "no relevant document found" |
| Comparing multiple documents | Weak | Reads required documents in sequence |
| Large document sets | Accuracy drops as size grows | Filters via table of contents, minimal impact |
| Citing sources | Scored fragments | Concrete: "I referenced page X of regulation Y" |
Because Skill Mode keeps a history of which documents it read to reach an answer, users can audit "how the AI thought" after the fact. That auditability is a huge confidence boost for business use.
4. Real Usage Scenarios -- What Actually Differs
Let's look at concrete cases. Imagine an HR knowledge base with 20 documents: employment regulations, HR evaluation policy, harassment response manual, salary/bonus/severance regulations, and so on.
Scenario 1: "Compare evaluation interview frequency between the employment regulations and the HR evaluation policy"
- With RAG: Only fragments from "employment regulations" get retrieved, returning "once a year." Fragments from the HR evaluation policy never come back, so the comparison falls apart. Worst case, the AI invents "the HR evaluation policy says every six months."
- With Skill Mode: The AI selects both "employment regulations" and "HR evaluation policy" from the table of contents, reads the relevant sections in each, and accurately replies: "Employment regulations specify once per year; the HR evaluation policy specifies quarterly."
Scenario 2: "Walk me through the process of returning from parental leave"
- With RAG: It collects fragments containing "parental leave" but can't integrate information that spans multiple regulations -- pre-return procedures, evaluation impact, etc. -- so the answer ends up one-sided.
- With Skill Mode: It reads several parental-leave-related regulations and returns a chronologically organized answer: pre-return procedures → adjustments at return → impact on subsequent evaluations.
Scenario 3: "How do I issue an API key?" (no such document)
- With RAG: It forcibly pulls fragments from unrelated documents and fabricates plausible-sounding steps.
- With Skill Mode: After consulting the table of contents, it states clearly: "This information is not included in the registered documents." and suggests reaching out to the responsible team.
For business use, the latter is unmistakably the safer choice.
5. Why "Navigate from a Table of Contents" Suits Internal Knowledge
Internal knowledge has properties unlike the unstructured sprawl of the open web:
- Structured: regulations are organized into chapters, manuals into procedures, FAQs into categories
- Updated at the document level: revising a regulation usually means replacing the whole document
- Accuracy is mission-critical: legal, HR, and accounting cannot afford misinterpretation
These properties fit "navigate from a table of contents" far better than RAG.
Monoshiri AI doubled down on that fit. When customers add documents to a folder, the AI automatically builds semantic groupings and a table of contents, and every time a question comes in, it navigates from that table of contents to the documents it needs to read. As customers add or replace documents, the table of contents updates automatically too -- so operational overhead drops dramatically compared with RAG.
6. What Monoshiri AI Promises Our Customers
With the move to Skill Mode, Monoshiri AI commits to three things:
1. We say "I don't know" clearly when we don't know
For questions not covered by the knowledge base, we return a clear "there is no matching record" instead of plausible-sounding fabrication. This is the single most important rule for preventing operational mistakes.
2. We always cite sources
Every AI answer comes with "which part of which document was read to produce it". So that whoever reads the answer can immediately verify against the original document, sources include concrete file names and section references.
3. We hold accuracy steady as documents grow
Internal knowledge inevitably accumulates. Because Skill Mode filters via a table of contents, accuracy stays stable as documents reach 100, 500, or 1000. You won't experience "it answered well at first, then got worse after we added more documents."
Conclusion -- For AI Knowledge, Accuracy Beats Speed
General-purpose AI like ChatGPT and Claude have raised expectations that "you can ask AI anything." But what a knowledge AI for business needs isn't the fluent answers of a general-purpose model -- it's accurate answers grounded in your own documents.
When we placed "accuracy" at the very top of our technology selection criteria, we concluded that Skill Mode fits our customers' workflows better than RAG.
If you've held back from deploying AI to your internal knowledge base because "what if it lies," we encourage you to experience the answer quality of Skill Mode firsthand.
- Features → What Monoshiri AI can do
- Pricing → Try free for 30 days
- Comparison → How we differ from other AI knowledge SaaS
Related articles
- What is RAG? A Plain-Language Guide to Transforming Internal Document Search
- Is RAG Already Outdated? Knowledge Base Design in the Long-Context Era
- How to Search Internal Documents with AI -- Differences from Keyword Search and Steps to Roll Out
For readers who want the technical details: A more in-depth, developer-perspective write-up of the Skill Mode migration -- including the technical background and implementation -- is available on the developer's personal Qiita post (in Japanese): RAG をやめました -- ナレッジAI SaaS「ものしりAI」 が Corpus2Skill (skill モード) に全面移行した理由.
Share this article
Related Articles

Is "RAG Is Dead" Really True? 6 Criteria for Internal Knowledge AI
With long-context LLMs on the rise, many claim "RAG is no longer needed." We sort out the cases where it genuinely isn't, and the cases where RAG is still essential, using six decision axes for choosing an internal knowledge AI.

What Is RAG? A Plain-English Guide to the Technology Reshaping Internal Document Search
A non-engineer's guide to RAG (Retrieval-Augmented Generation). Covers the limits of traditional internal document search, the changes RAG brings, and key points for enterprise adoption.

Is RAG Obsolete? Designing Knowledge Bases in the Long-Context Era
With 1M-token long-context models on the rise, some say RAG is no longer needed. We examine the claim from five angles -- cost, capacity, permissions, accuracy, and updates -- and show the current best answer for enterprise knowledge bases.
Try Monoshiri AI for free
Just upload your documents and start asking AI. Try our free plan with unlimited users.
Get Started FreeNo credit card required / Start in 1 minute