"AI agents," "multi-agent systems," "agentic RAG" -- as 2026 unfolds, the vocabulary around generative AI is turning over faster than ever. For information systems departments and DX teams, it can be hard to see what actually matters: "When all is said and done, what should we adopt for our own internal knowledge?"
This article first sorts through the 2025-2026 trends in AI agents, the latest LLMs, and enterprise generative AI use. From there, we explain -- concretely -- how to apply them to internal knowledge without being swept up by the hype, using the practical axes of accuracy, permissions, and operations.
What You'll Learn
- The major trends in 2026 AI agents and the latest LLMs (with the latest research data)
- How enterprise RAG and internal knowledge use are changing
- A practical framework for applying these trends to your own internal knowledge without chasing buzzwords
- Where Monoshiri AI fits in terms of accuracy, permissions, and operations
1. 2026 AI Agent Trends -- From "Standalone Chat" to "Collaborating Agents"
From 2025 into 2026, the protagonist of enterprise AI has been shifting from "one clever chatbot" to systems in which multiple specialized agents divide the work and collaborate.
The research firm Gartner predicts that by the end of 2026, 40% of enterprise applications will have AI agents embedded in them (compared to less than 5% in 2025). Inquiries about multi-agent systems also surged from Q1 2024 to Q2 2025, and the numbers reflect how the industry's focus has moved from "single models" to "designing and connecting agents."
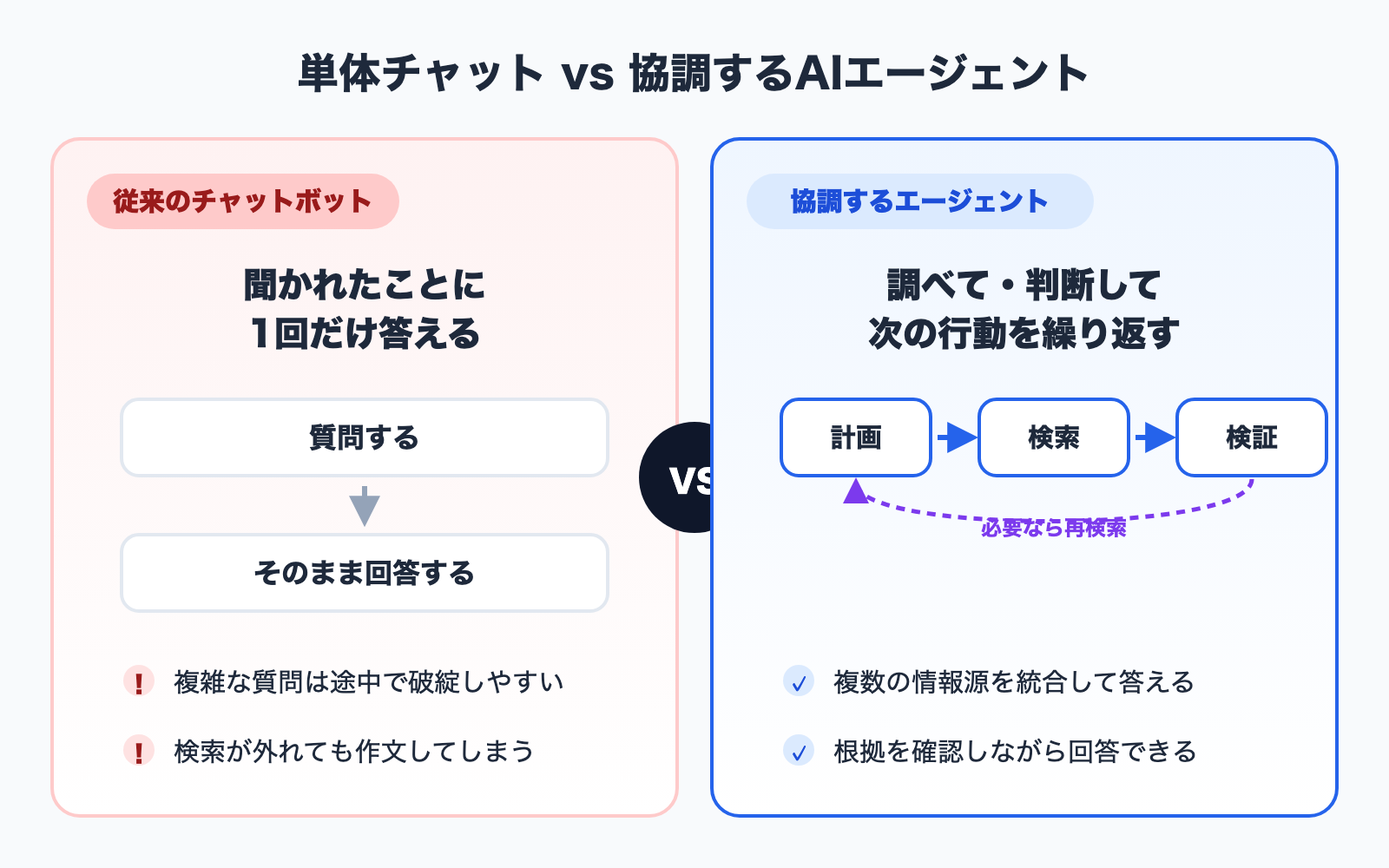
By an AI agent here, we mean -- in a single phrase -- "an AI that, given a goal, works out the steps on its own and advances the task while calling on the tools and data it needs." Where a traditional chatbot simply "answers a question once," an agent repeats a cycle of "investigate, decide, then determine the next action."
Standard Protocols Make "Connecting Things Up" Mainstream
The spread of standard protocols that let agents access internal data and tools is another major change in 2026. A leading example is Anthropic's MCP (Model Context Protocol). MCP has gained traction as a "common standard for connecting AI to external data and tools," bringing integrations that each service used to build individually much closer to plug-and-play.
This connects directly to internal knowledge use. If the knowledge base that handles your internal documents supports a standard protocol, you can access internal information directly from the AI tools you already use every day.
2. The Latest LLM Trends -- From "One Strongest Model" to "Picking the Right Tool for the Job"
The world of LLMs (large language models) also looks different in 2026.
Among major players such as OpenAI, Google, and Anthropic, who comes out ahead now routinely changes depending on the task or benchmark. According to Menlo Ventures' data from the latter half of 2025, Anthropic accounts for about 40% and OpenAI about 27% of enterprise LLM API spending -- so it is no longer a landscape dominated overwhelmingly by a single company.
What deserves even more attention is the move toward small, specialized models (SLMs: Small Language Models). Gartner predicts that by 2027, organizations will use small, task-specific AI models at least three times more than general-purpose large models. Rather than running everything through a giant model, the idea of balancing cost and accuracy according to the use case is spreading.
The implication for IT and DX teams is clear. Rather than chasing "which model is the strongest," what matters is choosing a system that fits your own use case. For internal knowledge, what's required is not creativity but accuracy, clearly stated sources, and the safe handling of data.
Models keep getting swapped out. That's exactly why -- rather than depending too heavily on any single model -- the real question is how you design a system that can "pull internal information out safely and accurately."
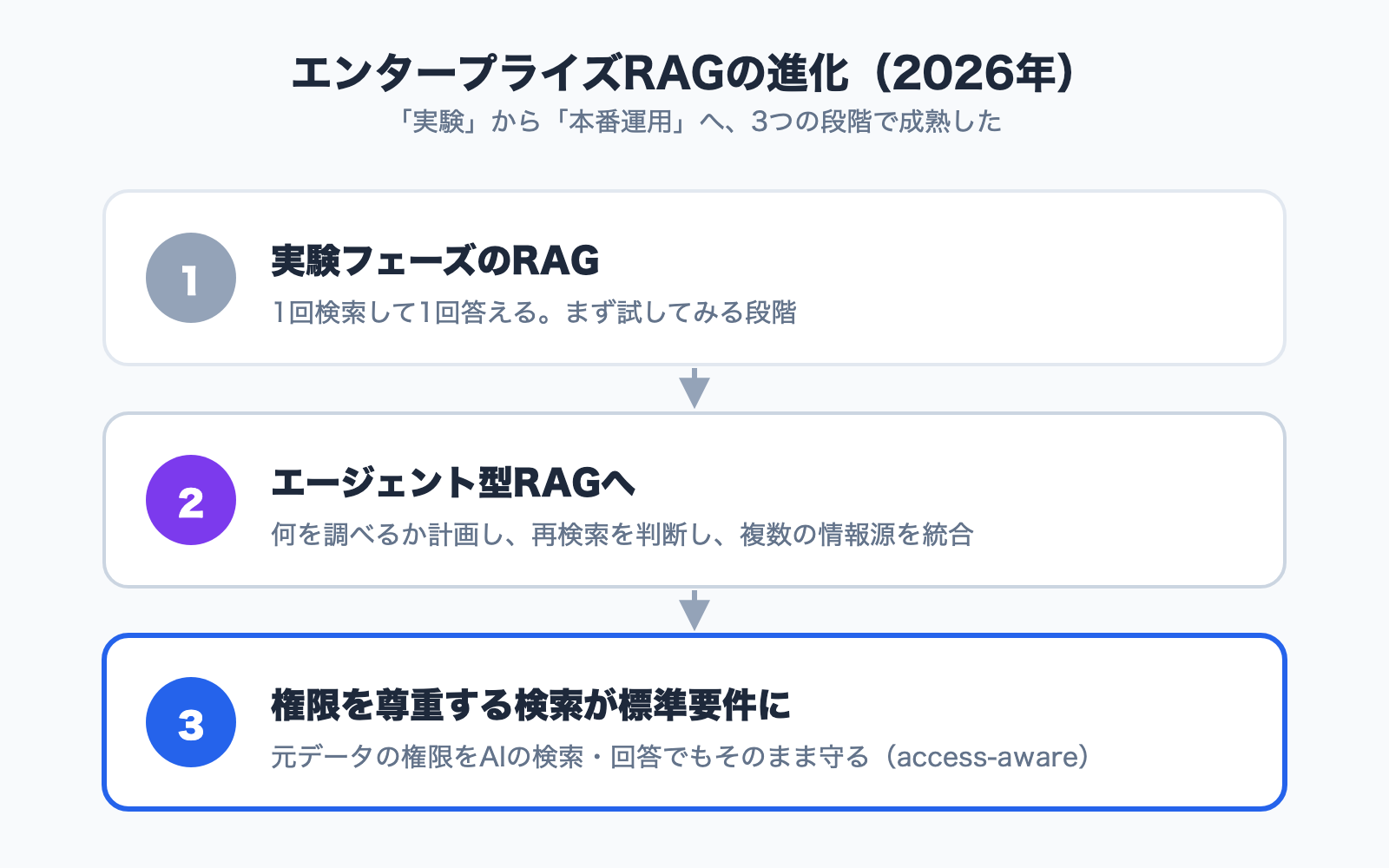
3. Trends in Enterprise RAG and Internal Knowledge Use -- From "Experiment" to "Production"
RAG (Retrieval-Augmented Generation, a mechanism that has the AI search for relevant documents before answering), the core technology behind internal knowledge use, has also matured considerably in 2026. For the basics of RAG, see What Is RAG? A Plain-English Guide to the Technology Reshaping Internal Document Search.
Multiple studies point to the same three things.
(1) From Experiment Phase to Production Phase
One survey finds that 71% of organizations are using generative AI in some area of their operations. RAG has shifted from "a technology to try out" to a production architecture where accuracy, compliance, and real-time performance are on the line.
(2) Evolution into "Agentic RAG"
Where traditional RAG meant "search once, answer once," agentic RAG plans what to investigate, decides whether to search again based on the results, and integrates multiple sources before answering. In other words, search is becoming not a passive process but an active layer of reasoning.
(3) "Access-Aware Retrieval" Becomes a Must
And what IT and DX teams should watch most closely is permission control. In 2026 enterprise RAG, "preserving the permissions set on the original data even in AI search and answers" is becoming a standard requirement. A design where anyone who asks the AI can surface confidential information is no longer acceptable.
At the same time, running RAG in production surfaces structural limits of its own. There's the ambiguity of sources that arises from splitting documents into small fragments (chunks), and hallucinations (plausible-sounding wrong answers) when retrieval misses. We cover this in detail in What Are the Limits of RAG? Preventing Hallucinations with Skill Mode, Explained with Real Examples.
4. Three Practical Axes for Not Getting Swept Up by the Hype
Taking these trends together, it becomes clear that however appealing the latest buzzwords are, applying them directly to your own internal knowledge use is risky. The practical axes IT and DX teams should hold onto come down to these three.
Axis 1. Accuracy -- Is It a "Grounded Answer," Not Just a "Plausible-Sounding" One?
What matters most for internal knowledge is not creative writing but accuracy. The more a department -- legal, HR, accounting -- cannot afford errors, the more it values this. Check whether the answer shows the internal documents it was grounded in, and whether the system is designed not to force an answer when retrieval misses.
Axis 2. Permissions -- Can You Control "Who Can Access Which Information"?
The information you're allowed to show differs by department and by project. You must avoid a state where anyone who asks the AI can surface company-wide confidential information. Whether you can set access rights at a granularity such as the folder level, and whether data is completely isolated per organization (tenant), will make or break adoption.
Axis 3. Operations -- Is It Designed to Keep Being Used, and to Get Used?
No matter how sophisticated the mechanism, it won't take root unless it's placed where employees work every day. Can people access it naturally from the chat tools they already use, from LINE, or from your own website? And is the operational burden and cost of updating documents easy to predict? What pays off after adoption is this unglamorous "operability."
5. Mapping Monoshiri AI onto These Three Axes
Finally, let's lay out -- on a factual basis -- where the enterprise knowledge base SaaS "Monoshiri AI" fits, viewed through the three practical axes above.
Accuracy: A "Skill Mode" That Shows Sources and Doesn't Force Answers
Monoshiri AI used RAG when the service first launched, but to resolve the issues that surfaced in production -- the ambiguity of sources caused by chunking, and wrong answers when retrieval misses -- it migrated entirely to skill mode (Corpus2Skill) in 2026. For uses where "accuracy" is a prerequisite, such as internal policies, manuals, and FAQs, it emphasizes a design that answers while showing the supporting sources. We've published the reasoning behind this decision in our article on why we left RAG.
Because answers show the documents that served as their source, users can check the original document whenever they need to.
Permissions: Folder-Level Access Rights and Complete Tenant Isolation
Monoshiri AI manages documents at the folder level and lets you set access rights per folder. You can organize knowledge by department or by project and operate it so that "only the people who should see it can see it."
Furthermore, data is completely isolated per organization (tenant), with storage and search indexes kept separate for each company. Data is stored in data centers within Japan (Tokyo) and encrypted both in transit and at rest. We also clearly state our policy of not using user data to train models. For details, see Security and Information Management.
Operations: Access Points That Blend into Daily Work, and a Flat Rate with Unlimited Users
With Monoshiri AI, you can start simply by uploading internal documents -- no specialized knowledge required. Its access points are designed so you can ask your internal information directly from the places you already work, through LINE integration, a web chat widget you can embed in your own site, and the MCP integration of the standard protocol mentioned earlier.
On cost, it uses a flat-rate model with unlimited users on every plan. You can start with the free plan, and paid plans begin from 2,980 yen/month. Because the price doesn't balloon as your user count grows, the cost of a company-wide rollout is easy to forecast. For details, see Pricing.
Chasing the latest buzzwords is not the goal in itself. Judging "whether it actually works for your own operations" across the three axes of accuracy, permissions, and operations is the most practical decision-making framework for internal knowledge use in 2026.
Summary
We've covered the 2026 trends in AI agents, the latest LLMs, and enterprise RAG, along with how to apply them to internal knowledge use. Here are the key points.
- AI agents are moving from "standalone chat" to "collaborating agents": Gartner predicts that by the end of 2026, 40% of enterprise applications will have AI agents embedded. Standard protocols such as MCP are making "connecting things up" mainstream
- LLMs are moving from "one strongest model" to "picking the right tool for the job": who comes out ahead among the major players is fluid, and the shift toward small, specialized models is advancing. For internal knowledge, accuracy, sources, and safety are what's on the line
- Enterprise RAG is moving from "experiment" to "production": agentic RAG and access-aware retrieval are becoming standard requirements
- The three axes for not getting swept up by the hype are "accuracy, permissions, and operations": judge by whether answers are grounded, whether you can control access rights, and whether it will keep being used
The latest trends are material for sharpening your own decision-making framework. A good place to start is simply thinking through, across the three axes of accuracy, permissions, and operations, "which business area to begin with, and with what documents."
Share this article
Related Articles
![Dify vs Monoshiri AI -- Choosing the Right Internal Knowledge AI for Your Team [2026 Edition]](/blog/dify-vs-monoshiri/header.jpg)
Dify vs Monoshiri AI -- Choosing the Right Internal Knowledge AI for Your Team [2026 Edition]
A practical comparison of Dify and Monoshiri AI across setup effort, Slack integration, knowledge ingestion, and model selection. Find out which fits engineering-led teams and which fits IT and business-led teams.

From 'Search' to 'Ask' -- The New Standard for Internal Information Access in the AI Era
Internal information that traditional keyword search couldn't find is now instantly accessible by simply asking AI. This article explains semantic search and RAG in plain language, introducing a paradigm shift in how organizations access knowledge.
Try Monoshiri AI for free
Just upload your documents and start asking AI. Try our free plan with unlimited users.
Get Started FreeNo credit card required / Start in 1 minute